本文是Android虚拟机系列文章的第二篇,会介绍Andorid系统上曾经使用过的Dalvik虚拟机。后面还会有一篇文章讲解Android系统上现在使用的虚拟机:ART。
本系列的相关文章如下:
也许有人会问,既然Dalvik虚拟机都已经被废弃了,为什么我们还要了解它呢?出于下面的原因,让我觉得还是有必要了解一下Dalvik虚拟机的:
- Dalvik留下的很多机制在现在的Android系统是一样适用的,例如Dalvik指令,dex文件
- 并非每个人都是在最新版本的Android系统上工作
- 了解一项技术曾经的历史和演进过程,有助于增加对于现在状态的理解
Dalvik是Google专门为Android操作系统开发的虚拟机。它支持.dex(即“Dalvik Executable”)格式的Java应用程序的运行。.dex格式是专为Dalvik设计的一种压缩格式,适合内存和处理器速度有限的系统。
Dalvik由Dan Bornstein编写,名字来源于他的祖先曾经居住过的小渔村达尔维克(Dalvík),位于冰岛。
栈 VS 寄存器
大多数虚拟机都是基于堆栈架构的,例如前面提到的HotSpot JVM。然而Dalvik虚拟机却恰好不是,它是基于寄存器架构的虚拟机。
对于基于栈的虚拟机来说,每一个运行时的线程,都有一个独立的栈。栈中记录了方法调用的历史,每有一次方法调用,栈中便会多一个栈桢。最顶部的栈桢称作当前栈桢,其代表着当前执行的方法。栈桢中通常包含四个信息:
- 局部变量:方法参数和方法中定义的局部变量
- 操作数栈:后入先出的栈
- 动态连接:指向运行时常量池该栈桢所属方法的引用
- 返回地址:当前方法的返回地址
栈帧的结构如下图所示:

基于堆栈架构的虚拟机的执行过程,就是不断在操作数栈上操作的过程。例如,对于计算“1+1”的结果这样一个计算,基于栈的虚拟机需要先将这两个数压入栈,然后通过一条指针对栈顶的两个数字进行加法运算,然后再将结果存储起来。其指令集会是这样子:
iconst_1
iconst_1
iadd
istore_0
而对于基于寄存器的虚拟机来说执行过程是完全不一样的。该类型虚拟机会将运算的参数放至寄存器中,然后在寄存器上直接进行运算。因此如果是基于寄存器的虚拟机,其指令可能会是这个样子:
mov eax,1
add eax,1
这两种架构哪种更好呢?
很显然,既然它们同时存在,那就意味着它们各有优劣,假设其中一种明显优于另外一种,那劣势的那一种便就不会存在了。
如果我们对这两种架构进行对比,我们会发现它们存在如下的区别:
- 基于栈的架构具有更好的可移植性,因为其实现不依赖于物理寄存器
- 基于栈的架构通常指令更短,因为其操作不需要指定操作数和结果的地址
- 基于寄存器的架构通常运行速度更快,因为有寄存器的支撑
- 基于寄存器的架构通常需要较少的指令来完成同样的运算,因为不需要进行压栈和出栈
dex文件
如果我们对比jar文件和dex文件,就会发现:dex文件格式相对来说更加的紧凑。
jar文件以class为区域进行划分,在连续的class区域中会包含每个class中的常量,方法,字段等等。而dex文件按照类型(例如:常量,字段,方法)划分,将同一类型的元素集中到一起进行存放。这样可以更大程度上避免重复,减少文件大小。
两种文件格式的对比如下图所示:
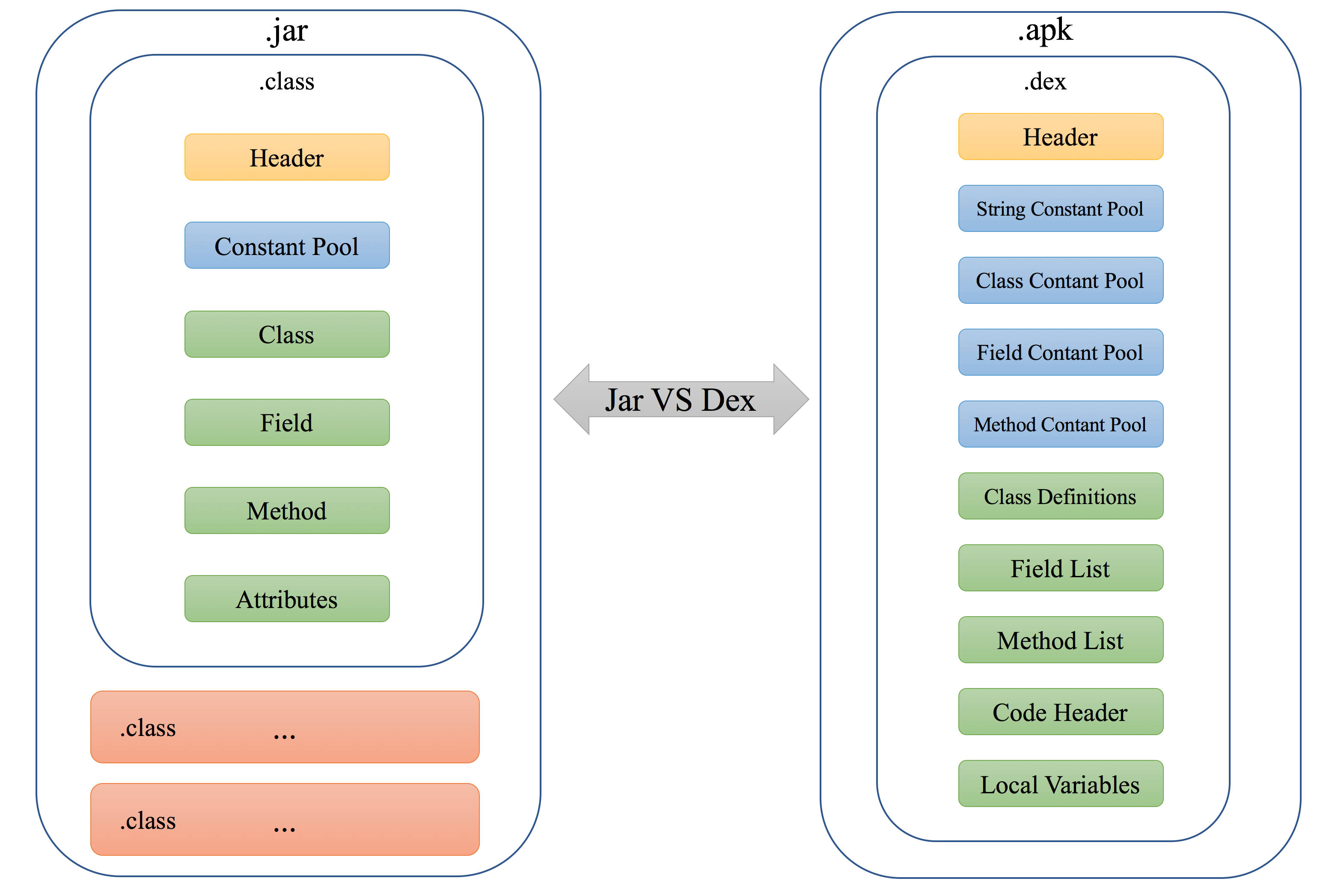
dex文件的完整格式参见这里:Dalvik 可执行文件格式。
由于Dex文件相较于Jar来说,对同一类型的元素进行了规整,并且去掉了重复项。因此通常情况下,对于同样的内容,前者比后者文件要更小。以下是Google给出的数据,从这个对比数据可以看出,两者的差距还是很大的。
| 内容 | 未压缩jar包 | 已压缩jar包 | 未压缩dex文件 |
|---|---|---|---|
| 系统库 | 100% | 50% | 48% |
| Web浏览器 | 100% | 49% | 44% |
| 闹钟应用 | 100% | 52% | 44% |
为了便于开发者分析dex文件中的内容,Android系统中内置了dexdump工具。借助这个工具,我们可以详细了解到dex的文件结构和内容。以下是这个工具的帮助文档。在接下来的内容中,我们将借这个工具来反编译出dex文件中的Dalvik指令。
angler:/ # dexdump
dexdump: no file specified
Copyright (C) 2007 The Android Open Source Project
dexdump: [-c] [-d] [-f] [-h] [-i] [-l layout] [-m] [-t tempfile] dexfile...
-c : verify checksum and exit
-d : disassemble code sections
-f : display summary information from file header
-h : display file header details
-i : ignore checksum failures
-l : output layout, either 'plain' or 'xml'
-m : dump register maps (and nothing else)
-t : temp file name (defaults to /sdcard/dex-temp-*)
Dalvik指令
Dalvik虚拟机一共包含两百多条指令。读者可以访问下面这个网址获取这些指令的详细信息:Dalvik 字节码。
我们这里不会对每条指令做详细讲解,建议读者大致浏览一下上面这个网页。
下面以一个简单的例子来让读者对Dalvik指令有一个直观的认识。
下面是一个Activity的源码,在这个Activity中,我们定义了一个sum方法,进行两个整数的相加。然后在Activity的onCreate方法中,在setContentView之后,调用这个sum方法并传递1和2,然后再将结果通过System.out.print进行输出。这段代码很简单,简单到几乎没有什么实际的作用,不过这不要紧,因为这里我们的目的仅仅想看一下我们编写的源码最终得到的Dalvik指令究竟是什么样的。
package test.android.com.helloandroid;
import android.app.Activity;
import android.os.Bundle;
public class MainActivity extends Activity {
int sum(int a, int b) {
return a + b;
}
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
System.out.print(sum(1,2));
}
}
将这个工程编译之后获得了APK文件。APK文件其实是一种压缩格式,我们可以使用任何可以解压Zip格式的软件对其解压缩。解压缩之后的文件列表如下所示:
├── AndroidManifest.xml
├── META-INF
│ ├── CERT.RSA
│ ├── CERT.SF
│ └── MANIFEST.MF
├── classes.dex
├── res
│ ├── layout
│ │ └── activity_main.xml
│ ├── mipmap-hdpi-v4
│ │ ├── ic_launcher.png
│ │ └── ic_launcher_round.png
│ ├── mipmap-mdpi-v4
│ │ ├── ic_launcher.png
│ │ └── ic_launcher_round.png
│ ├── mipmap-xhdpi-v4
│ │ ├── ic_launcher.png
│ │ └── ic_launcher_round.png
│ ├── mipmap-xxhdpi-v4
│ │ ├── ic_launcher.png
│ │ └── ic_launcher_round.png
│ └── mipmap-xxxhdpi-v4
│ ├── ic_launcher.png
│ └── ic_launcher_round.png
└── resources.arsc
其他的文件不用在意,这里我们只要关注dex文件即可。我们可以通过adb push命令将classes.dex文件拷贝到手机上,然后通过手机上的dexdump命令来进行分析。
直接输入dexdump classes.dex会得到一个非常长的输出。下面是其中的一个片段:
...
Class #40 -
Class descriptor : 'Ltest/android/com/helloandroid/MainActivity;'
Access flags : 0x0001 (PUBLIC)
Superclass : 'Landroid/app/Activity;'
Interfaces -
Static fields -
Instance fields -
Direct methods -
#0 : (in Ltest/android/com/helloandroid/MainActivity;)
name : '<init>'
type : '()V'
access : 0x10001 (PUBLIC CONSTRUCTOR)
code -
registers : 1
ins : 1
outs : 1
insns size : 4 16-bit code units
catches : (none)
positions :
0x0000 line=6
locals :
0x0000 - 0x0004 reg=0 this Ltest/android/com/helloandroid/MainActivity;
Virtual methods -
#0 : (in Ltest/android/com/helloandroid/MainActivity;)
name : 'onCreate'
type : '(Landroid/os/Bundle;)V'
access : 0x0004 (PROTECTED)
code -
registers : 5
ins : 2
outs : 3
insns size : 20 16-bit code units
catches : (none)
positions :
0x0000 line=14
0x0003 line=15
0x0008 line=17
0x0013 line=18
locals :
0x0000 - 0x0014 reg=3 this Ltest/android/com/helloandroid/MainActivity;
0x0000 - 0x0014 reg=4 savedInstanceState Landroid/os/Bundle;
#1 : (in Ltest/android/com/helloandroid/MainActivity;)
name : 'sum'
type : '(II)I'
access : 0x0000 ()
code -
registers : 4
ins : 3
outs : 0
insns size : 3 16-bit code units
catches : (none)
positions :
0x0000 line=9
locals :
0x0000 - 0x0003 reg=1 this Ltest/android/com/helloandroid/MainActivity;
0x0000 - 0x0003 reg=2 a I
0x0000 - 0x0003 reg=3 b I
source_file_idx : 455 (MainActivity.java)
...
从这个片段中,我们看到了刚刚编写的MainActivity类的详细信息。包括每一个方法的名称,签名,访问级别,使用的寄存器等信息。
接下来,我们通过dexdump -d classes.dex来反编译代码段,以查看方法实现逻辑所对应的Dalvik指令。
通过这个命令,我们得到sum方法的指令如下:
[019f98] test.android.com.helloandroid.MainActivity.sum:(II)I
0000: add-int v0, v2, v3
为了看懂add-int指令的含义,我们可以查阅Dalvik指令的说明文档:
| Mnemonic / Syntax | Arguments | Description |
|---|---|---|
| binop vAA, vBB, vCC 90: add-int |
A: destination register or pair (8 bits) B: first source register or pair (8 bits) C: second source register or pair (8 bits) |
Perform the identified binary operation on the two source registers, storing the result in the destination register. |
这段说明文档的含义是:add-int是一个需要两个操作数的指令,其指令格式是:add-int vAA, vBB, vCC。其指令的运算过程,是将后面两个寄存器中的值进行(加)运算,然后将结果放在(第一个)目标寄存器中。
很显然,对应到add-int v0, v2, v3就是将v2和v3两个寄存器的值相加,并将结果存储到v0寄存器上。这正好是对应了我们所写的代码:return a + b;。
下面,我们再看一下稍微复杂一点的onCreate方法其对应的Dalvik指令:
[019f60] test.android.com.helloandroid.MainActivity.onCreate:(Landroid/os/Bundle;)V
0000: invoke-super {v3, v4}, Landroid/app/Activity;.onCreate:(Landroid/os/Bundle;)V // method@0001
0003: const/high16 v0, #int 2130903040 // #7f03
0005: invoke-virtual {v3, v0}, Ltest/android/com/helloandroid/MainActivity;.setContentView:(I)V // method@0318
0008: sget-object v0, Ljava/lang/System;.out:Ljava/io/PrintStream; // field@02e0
000a: const/4 v1, #int 1 // #1
000b: const/4 v2, #int 2 // #2
000c: invoke-virtual {v3, v1, v2}, Ltest/android/com/helloandroid/MainActivity;.sum:(II)I // method@0319
000f: move-result v1
0010: invoke-virtual {v0, v1}, Ljava/io/PrintStream;.print:(I)V // method@02d7
0013: return-void
同样,通过查阅指令的说明文档,我们可以知道这里牵涉到的几条指令含义如下:
invoke-super: 调用父类中的方法const/high16: 将指定的字面值的高16位拷贝到指定的寄存器中,这是一个16bit的操作invoke-virtual: 调用一个virtual方法sget-object: 获取类中static字段的对象,并存放到指定的寄存器上const/4: 将指定的字面值拷贝到指定的寄存器中,这是一个32bit的操作move-result: 该指令紧接着invoke-xxx指令,将上一条指令的结果移动到指定的寄存器中return-void: void方法返回
由此,我们便能看懂这段指令的含义了。甚至我们已经具备了阅读任何Dalvik代码的能力,因为无非就是明白每个指令的含义罢了。
单纯的阅读指令的说明文档可能很枯燥,也不容易记住。建议读者继续写一些复杂的代码然后通过反编译方式查看其对应的虚拟机指令来进行学习。或者对已有的项目进行反编译来查看其机器指令。也许一些读者觉得,开发者根本不必去阅读这些原本就不准备给人类阅读的机器指令。但实际上,对于底层指令越是熟悉,对底层机制越是了解,往往能让我们写出越是高效的程序来,因为一旦我们深刻理解机制背后的运行原理,就可以避过或者减少一些不必要的重复运算。再者,具备对于底层指令的理解能力,也为我们分析解决一些从源码层无法分析的问题提供了一个新的手段。
最后笔者想提醒一下,即便在ART虚拟机时代,这里学习的Dalvik指令和反编译手段仍然是没有过时的。因为这种分析方式是依然可用的。这也是为什么我们要讲解Dalvik虚拟机的原因。
Dalvik启动过程
注:自Android 5.0开始,Dalvik虚拟机已经被废弃,其源码也已经被从AOSP中删除。因此想要查看其源码,需要获取Android 4.4或之前版本的代码。本小节接下来贴出的源码取自AOSP代码TAG android-4.4_r1。
Dalvik虚拟机的源码位于下面这个目录中:
/dalvik/vm/
在其他的文章(这里, 还有这里)中,我们讲解了系统的启动过程,并且也介绍了zygote进程。我们提到zygote进程会启动虚拟机,但是却没有深入了解过虚拟机是如何启动的,而这正是本文接下来要讲解的内容。
zygote进程是由app_process启动的,我们来回顾一下app_process main函数中的关键代码:
// app_process.cpp
int main(int argc, char* const argv[])
{
...
if (zygote) {
runtime.start("com.android.internal.os.ZygoteInit", args, zygote);
} else if (className) {
runtime.start("com.android.internal.os.RuntimeInit", args, zygote);
} else {
fprintf(stderr, "Error: no class name or --zygote supplied.\n");
app_usage();
LOG_ALWAYS_FATAL("app_process: no class name or --zygote supplied.");
return 10;
}
}
这里通过runtime.start方法指定入口类启动了虚拟机。虚拟机在启动之后,会以入口类的main函数为起点来执行。
runtime是AppRuntime类的对象,start方法是在AppRuntime类的父类AndroidRuntime中定义的方法。该方法中的关键代码如下:
// AndroidRuntime.cpp
void AndroidRuntime::start(const char* className, const char* options)
{
...
/* start the virtual machine */
JniInvocation jni_invocation;
jni_invocation.Init(NULL);
JNIEnv* env;
if (startVm(&mJavaVM, &env) != 0) { ①
return;
}
onVmCreated(env);
/*
* Register android functions.
*/
if (startReg(env) < 0) { ②
ALOGE("Unable to register all android natives\n");
return;
}
...
char* slashClassName = toSlashClassName(className);
jclass startClass = env->FindClass(slashClassName); ③
if (startClass == NULL) {
ALOGE("JavaVM unable to locate class '%s'\n", slashClassName);
/* keep going */
} else {
jmethodID startMeth = env->GetStaticMethodID(startClass, "main",
"([Ljava/lang/String;)V");
if (startMeth == NULL) {
ALOGE("JavaVM unable to find main() in '%s'\n", className);
/* keep going */
} else {
env->CallStaticVoidMethod(startClass, startMeth, strArray); ④
#if 0
if (env->ExceptionCheck())
threadExitUncaughtException(env);
#endif
}
}
free(slashClassName);
ALOGD("Shutting down VM\n"); ⑤
if (mJavaVM->DetachCurrentThread() != JNI_OK)
ALOGW("Warning: unable to detach main thread\n");
if (mJavaVM->DestroyJavaVM() != 0)
ALOGW("Warning: VM did not shut down cleanly\n");
}
这段代码主要逻辑如下:
- 通过
startVm方法启动虚拟机 - 通过
startReg方法注册Android Framework类相关的JNI方法 - 查找入口类的定义
- 调用入口类的
main方法 - 处理虚拟机退出前执行的逻辑
接下来我们先看startVm方法的实现,然后再看startReg方法。
AndroidRuntime::startVm方法有三百多行代码。但其逻辑却很简单,因为这个方法中的绝大部分代码都是在确定虚拟机的启动参数的值。这些值主要来自于许多的系统属性,这个方法中读取的属性以及这些属性的含义如下表所示:
| 属性名称 | 属性的含义 |
|---|---|
| dalvik.vm.checkjni | 是否要执行扩展的JNI检查,CheckJNI是一种添加额外JNI检查的模式;出于性能考虑,这些选项在默认情况下并不会启用。此类检查将捕获一些可能导致堆损坏的错误,例如使用无效/过时的局部和全局引用。如果这个值为false,则读取ro.kernel.android.checkjni的值 |
| ro.kernel.android.checkjni | 只读属性,是否要执行扩展的JNI检查。当dalvik.vm.checkjni为false,此值才生效 |
| dalvik.vm.execution-mode | Dalvik虚拟机的执行模式,即:所使用的解释器,下文会讲解 |
| dalvik.vm.stack-trace-file | 指定堆栈跟踪文件路径 |
| dalvik.vm.check-dex-sum | 是否要检查dex文件的校验和 |
| log.redirect-stdio | 是否将stdout/stderr转换成log消息 |
| dalvik.vm.enableassertions | 是否启用断言 |
| dalvik.vm.jniopts | JNI可选配置 |
| dalvik.vm.heapstartsize | 堆的起始大小 |
| dalvik.vm.heapsize | 堆的大小 |
| dalvik.vm.jit.codecachesize | JIT代码缓存大小 |
| dalvik.vm.heapgrowthlimit | 堆增长的限制 |
| dalvik.vm.heapminfree | 堆的最小剩余空间 |
| dalvik.vm.heapmaxfree | 堆的最大剩余空间 |
| dalvik.vm.heaptargetutilization | 理想的堆内存利用率,其取值位于0与1之间 |
| ro.config.low_ram | 该设备是否是低内存设备 |
| dalvik.vm.dexopt-flags | 是否要启用dexopt特性,例如字节码校验以及为精确GC计算寄存器映射 |
| dalvik.vm.lockprof.threshold | 控制Dalvik虚拟机调试记录程序内部锁资源争夺的阈值 |
| dalvik.vm.jit.op | 对于指定的操作码强制使用解释模式 |
| dalvik.vm.jit.method | 对于指定的方法强制使用解释模式 |
| dalvik.vm.extra-opts | 其他选项 |
注:Android系统中很多服务都有类似的做法,即:通过属性的方式将模块的配置参数外化。这样外部只要设置属性值即可以改变这些模块的内部行为。
这些属性的值会被读取并最终会被组装到initArgs中,并以此传递给JNI_CreateJavaVM函数来启动虚拟机:
// AndroidRuntime.cpp
if (JNI_CreateJavaVM(pJavaVM, pEnv, &initArgs) < 0) {
ALOGE("JNI_CreateJavaVM failed\n");
goto bail;
}
JNI_CreateJavaVM函数是虚拟机实现的一部分,因此该方法代码已经位于Dalvik中。具体的在这个文件中:/dalvik/vm/Jni.pp。
JNI_CreateJavaVM方法中的关键代码如下所示:
// Jni.cpp
jint JNI_CreateJavaVM(JavaVM** p_vm, JNIEnv** p_env, void* vm_args) {
const JavaVMInitArgs* args = (JavaVMInitArgs*) vm_args;
...
memset(&gDvm, 0, sizeof(gDvm));
JavaVMExt* pVM = (JavaVMExt*) calloc(1, sizeof(JavaVMExt));
pVM->funcTable = &gInvokeInterface;
pVM->envList = NULL;
dvmInitMutex(&pVM->envListLock);
UniquePtr<const char*[]> argv(new const char*[args->nOptions]);
memset(argv.get(), 0, sizeof(char*) * (args->nOptions));
...
JNIEnvExt* pEnv = (JNIEnvExt*) dvmCreateJNIEnv(NULL);
gDvm.initializing = true;
std::string status =
dvmStartup(argc, argv.get(), args->ignoreUnrecognized, (JNIEnv*)pEnv);
gDvm.initializing = false;
...
dvmChangeStatus(NULL, THREAD_NATIVE);
*p_env = (JNIEnv*) pEnv;
*p_vm = (JavaVM*) pVM;
ALOGV("CreateJavaVM succeeded");
return JNI_OK;
}
在这个函数中,会读取启动的参数值,并将这些值设置到两个全局变量中,它们是:
// Init.cpp
struct DvmGlobals gDvm;
struct DvmJniGlobals gDvmJni;
DvmGlobals这个结构体的定义非常之大,总计有约700行,其中存储了Dalvik虚拟机相关的全局属性,这些属性在虚拟机运行过程中会被用到。而gDvmJni中则记录了Jni相关的属性。
JNI_CreateJavaVM函数中最关键的就是调用dvmStartup函数。很显然,这个函数的含义是:Dalvik Startup。因此这个函数负责了Dalvik虚拟机的初始化工作,由于虚拟机本身也是有很多子模块和组件构成的,因此这个函数中调用了一系列的初始化方法来完成整个虚拟机的初始化工作,这其中包含:虚拟机堆的创建,内存分配跟踪器的创建,线程的启动,基本核心类加载等一系列工作,在这之后整个虚拟机就启动完成了。
这些方法是与Dalvik的实现细节紧密相关的,这里我们就不深入了,有兴趣的读者可以自行去学习。
虚拟机启动完成之后就可以用了。但对于Android系统来说,还有一些工作要做,那就是Android Framework相关类的JNI方法注册。我们知道,Android Framework主要是Java语言实现的,但其中很多类都需要依赖于native实现,因此需要通过JNI将两种实现衔接起来。例如,在第1章我们讲解Binder机制中的Parcel类就是既有Java层接口也有native层的实现。除了Parcel类,还有其他类也是类似的。并且,Framework中的类是几乎每个应用程序都可能会被用到的,为了减少每个应用程度单独加载的逻辑,因此虚拟机在启动之后直接就将这些类的JNI方法全部注册到虚拟机中了。完成这个逻辑的便是上面我们看到的startReg方法:
/*
* Register android functions.
*/
if (startReg(env) < 0) {
ALOGE("Unable to register all android natives\n");
return;
}
这个函数是在注册所有Android Framework中类的JNI方法,在AndroidRuntime类中,通过gRegJNI这个全局组数进行了记录了这些信息。这个数组包含了一百多个条目,下面是其中的一部分:
static const RegJNIRec gRegJNI[] = {
REG_JNI(register_android_debug_JNITest),
REG_JNI(register_com_android_internal_os_RuntimeInit),
REG_JNI(register_android_os_SystemClock),
REG_JNI(register_android_util_EventLog),
REG_JNI(register_android_util_Log),
REG_JNI(register_android_util_FloatMath),
REG_JNI(register_android_text_format_Time),
REG_JNI(register_android_content_AssetManager),
REG_JNI(register_android_content_StringBlock),
REG_JNI(register_android_content_XmlBlock),
REG_JNI(register_android_emoji_EmojiFactory),
REG_JNI(register_android_text_AndroidCharacter),
REG_JNI(register_android_text_AndroidBidi),
REG_JNI(register_android_view_InputDevice),
REG_JNI(register_android_view_KeyCharacterMap),
REG_JNI(register_android_os_Process),
REG_JNI(register_android_os_SystemProperties),
REG_JNI(register_android_os_Binder),
REG_JNI(register_android_os_Parcel),
...
};
这个数组中的每一项包含了一个函数,每个函数由Framework中对应的类提供,负责该类的JNI函数注册。这其中就包含我们在第二章提到的Binder和Parcel。
我们以Parcel为例来看一下:register_android_os_Parcel函数由android_os_Parcel.cpp提供,代码如下:
int register_android_os_Parcel(JNIEnv* env)
{
jclass clazz;
clazz = env->FindClass(kParcelPathName);
LOG_FATAL_IF(clazz == NULL, "Unable to find class android.os.Parcel");
gParcelOffsets.clazz = (jclass) env->NewGlobalRef(clazz);
gParcelOffsets.mNativePtr = env->GetFieldID(clazz, "mNativePtr", "I");
gParcelOffsets.obtain = env->GetStaticMethodID(clazz, "obtain",
"()Landroid/os/Parcel;");
gParcelOffsets.recycle = env->GetMethodID(clazz, "recycle", "()V");
return AndroidRuntime::registerNativeMethods(
env, kParcelPathName,
gParcelMethods, NELEM(gParcelMethods));
}
这段代码的最后是调用AndroidRuntime::registerNativeMethods对每个JNI方法进行注册,gParcelMethods包含了Parcel类中的所有JNI方法列表,下面是其中一部分:
static const JNINativeMethod gParcelMethods[] = {
{"nativeDataSize", "(I)I", (void*)android_os_Parcel_dataSize},
{"nativeDataAvail", "(I)I", (void*)android_os_Parcel_dataAvail},
{"nativeDataPosition", "(I)I", (void*)android_os_Parcel_dataPosition},
{"nativeDataCapacity", "(I)I", (void*)android_os_Parcel_dataCapacity},
{"nativeSetDataSize", "(II)V", (void*)android_os_Parcel_setDataSize},
{"nativeSetDataPosition", "(II)V", (void*)android_os_Parcel_setDataPosition},
{"nativeSetDataCapacity", "(II)V", (void*)android_os_Parcel_setDataCapacity},
...
}
总结起来这里的逻辑就是:
- Android Framework中每个包含了JNI方法的类负责提供一个
register_xxx方法,这个方法负责该类中所有JNI方法的注册 - 类中的所有JNI方法通过一个二维数组记录
gRegJNI中罗列了所有Framework层类提供的register_xxx函数指针,并以此指针来完成调用,以使得整个JNI注册过程完成
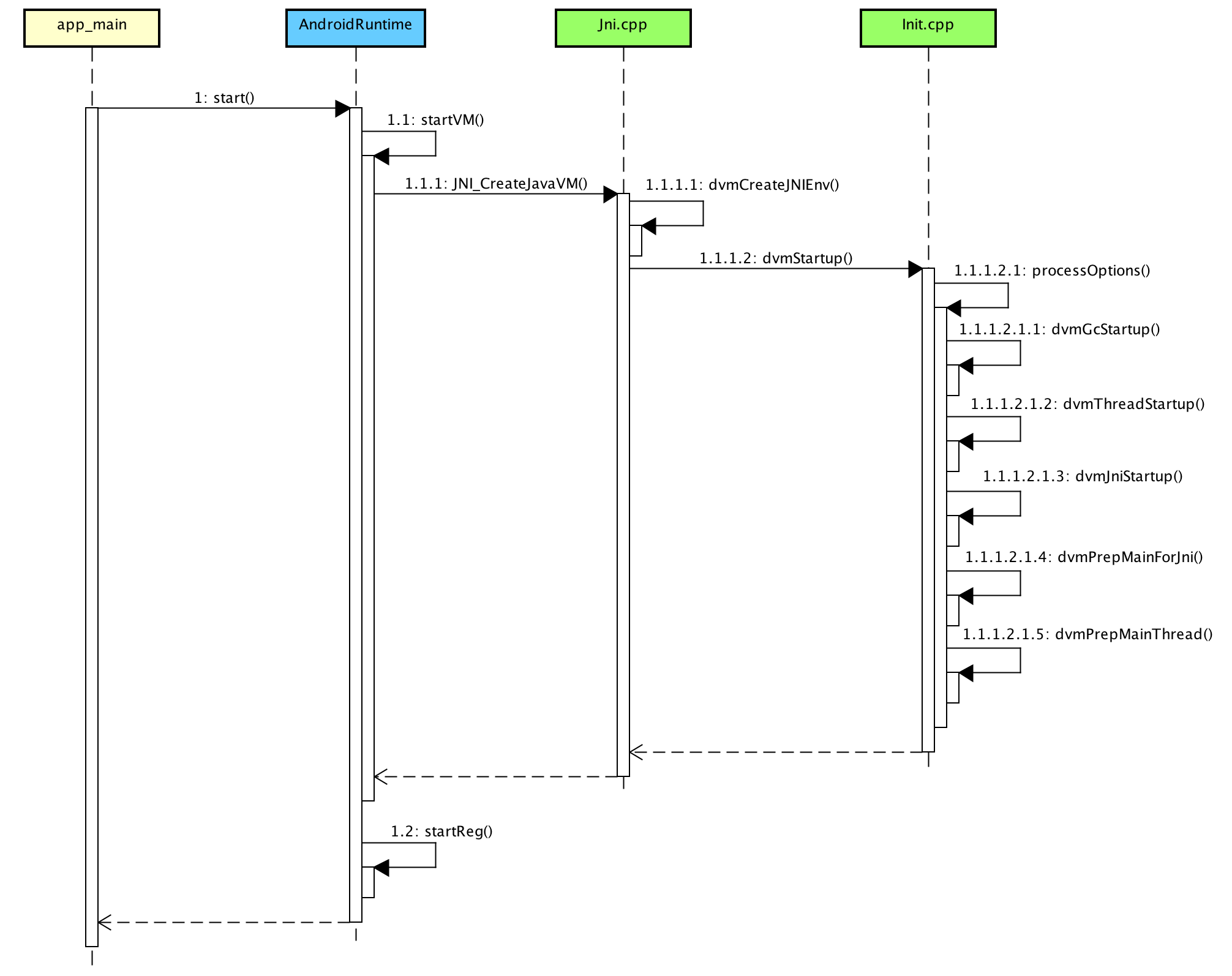
至此,Dalvik虚拟机的启动过程我们就讲解完了,下图描述了完整的Dalvik虚拟机启动过程:
程序的执行:解释与编译
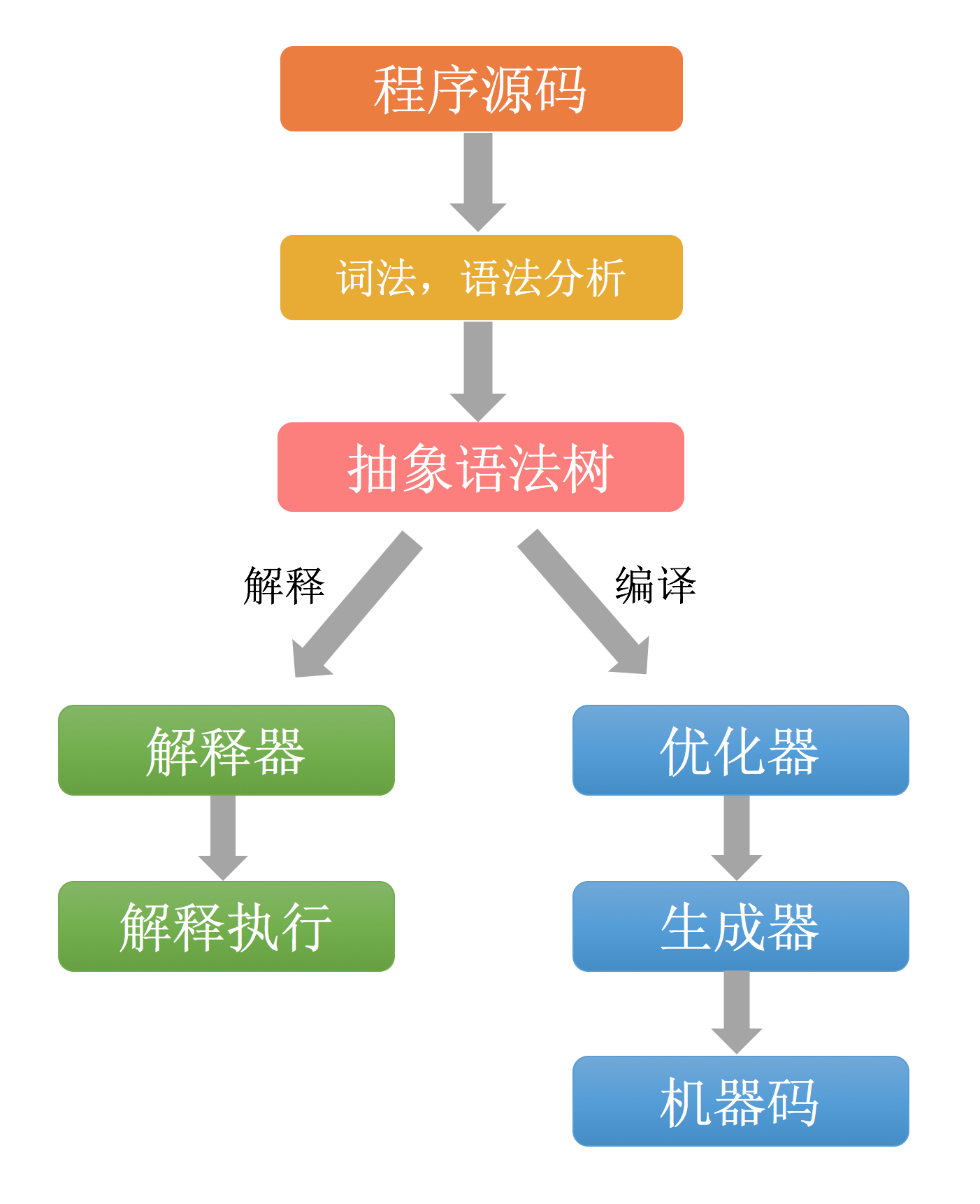
程序员通过源码的形式编写程序,而机器只能认识机器码。从编写完的程序到在机器上运行,中间必须经过一个转换的过程。这个转换的过程由两种做法,那就是:解释和编译。
- 解释是指:源程序由程序解释器边扫描边翻译执行,这种方式不会产生目标文件,因此如果程序执行多次就需要重复解释多次。
- 编译是指:通过编译器将源程序完整的地翻译成用机器语言表示的与之等价的目标程序。因此,这种方式只要编译一次,得到的产物可以反复执行。
许多脚本语言,例如JavaScript用的就是解释方式,因此其开发的过程中不牵涉到任何编译的步骤(注意,这里仅仅是指程序员的开发阶段,在虚拟机的内部解释过程中,仍然会有编译的过程,只不过对程序员隐藏了)。而对于C/C++这类静态编译语言来说,在写完程序之后到真正运行之前,必须经由编译器将程序编译成机器对应的机器码。
正如前面说过的观点那样:既然一个问题还存在两种解决方法,那么它们自然各有优势。
解释性语言通常都具有的一个优点就是跨平台:因为这些语言由解释器承担了不同平台上的兼容工作,而开发者不用关心这一点。相反,编译性语言的编译产物是与平台向对应的,Windows上编译出来的C++可执行文件(不使用交叉编译工具链)不能在Linux或者Mac运行。但反过来,解释性语言的缺点就是运行效率较慢,因为有很多编译的动作延迟到运行时来执行了,这就必要导致运行时间较长。
而Java语言介于完全解释和静态编译两者之间。因为无论是JVM上的class文件还是Dalvik上的dex文件,这些文件是已经经过词法和语法分析的中间产物。但这个产物与C/C++语言所对应的编译产物还不一样,因为Java语言的编译产物只是一个中间产物,并没有完全对应到机器码。在运行时,还需要虚拟机进行解释执行或者进一步的编译。
有些Java的虚拟机只包含解释器,有些只包含编译器。而在Dalvik在最早期的版本中,只包含了解释器,从Android 2.2版本开始,包含了JIT编译器。
下图描述了解释和编译的流程:
Dalvik上的解释器
解释器正如其名称那样:负责程序的解释执行。在Dalvik中,内置了三个解析器,分别是:
- fast: 默认解释器。这个解释器专门为平台优化过,因为其中包含了手写的汇编代码
- portable: 顾名思义,具有较好可移植性的解释器,因为这个解释器是用C语言实现的
- debug: 专门为debug和profile所用的解析器,性能较弱
用户可以通过设置属性来选择解释器,例如下面这条命令设定解释器为portable:
adb shell "echo dalvik.vm.execution-mode = int:portable >> /data/local.prop"
前面我们已经看到,Dalvik虚拟机在启动的时候会读取这个属性,因此当你修改了这个属性之后,需要重新启动才能使之生效。
Dalvik解释器的源码位于这个路径:
/dalvik/vm/mterp
portable是最先实现的解释器,这个解释器以单个C语言函数的形式实现的。但是为了改进性能,Google后来使用汇编语言重写了,这也就是fast解释器。为了使得这些汇编程序更容易移植,解释器的实现采用了模块化的方法:这使得允许每次开发特定平台上的特定操作码。
每个配置都有一个“config-*”文件来控制来源代码的生成。源代码被写入/dalvik/vm/mterp/out目录,Android编译系统会读取这里的文件。
熟悉解释器的最好方法就是看翻译生成的文件在“out”目录下的文件。
关于这部分内容我们就不深入展开了,有兴趣的读者可以自定阅读这部分代码。
Dalvik上的JIT
Java虚拟机的引入是将传统静态编译的过程进行了分解:首先编译出一个中间产物(无论是JVM的class文件格式还是Android的dex文件格式),这个中间产物是平台无关的。而在真正运行这个中间产物的时候,再由解释器将其翻译成具体设备上的机器码然后执行。
而虚拟机上的解释器通常只对运行到的代码进行机器码翻译。这样做效率就很低,因为有些代码可能要重复执行很多遍(例如日志输出),但每遍都要重新翻译。
而JIT就是为了解决这个问题而产生的,JIT在运行时进行代码的编译,这样下次再次执行同样的代码的时候,就不用再次解释翻译了,而是可以直接使用编译后的结果,这样就加快了执行的速度。但它并非编译所有代码,而是有选择性的进行编译,并且这个“选择性”是JIT编译器尤其需要考虑的。因为编译是一个非常耗时的事情,对于那些运行较少的“冷门”代码进行编译可能会适得其反。
总的来说,JIT在选择哪些代码进行编译时,有两种做法:
- Method JIT
- Trace JIT
第一种是以Java方法为单位进行编译。第二种是以代码行为单位进行编译。考虑到移动设备上内存较小(编译的过程需要消耗内存),因此Dalvik上的JIT以后一种做法为主。
实际上,对于JIT来说,最重要还是需要确定哪些代码是“热门”代码并需要编译,解决这个问题的做法如下图所示:
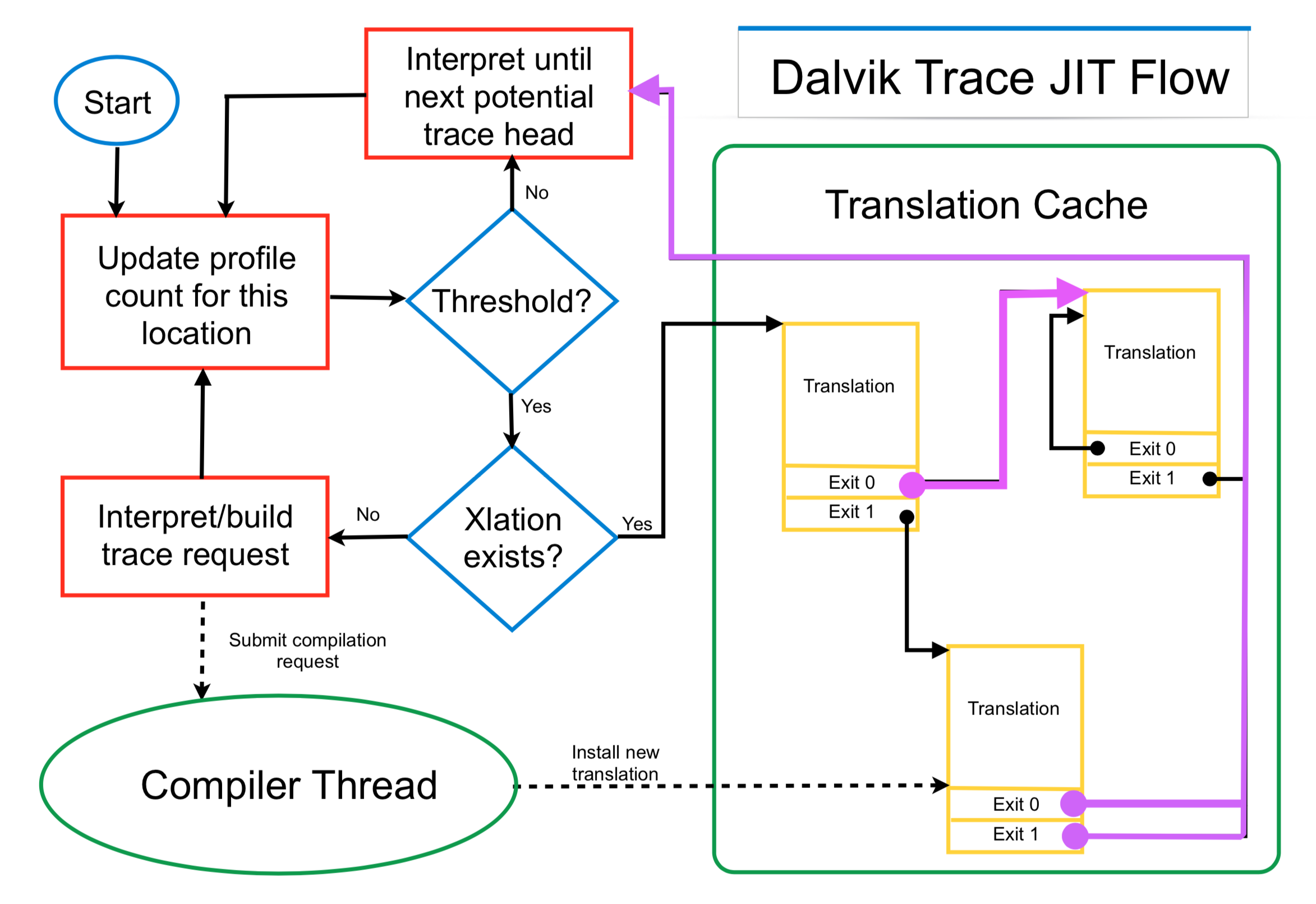
这个过程描述如下:
- 首先需要记录代码的执行次数
- 并设定一个“热门”代码的阈值,每次执行时都比对一下看看有没有到阈值
- 如果没有,则还是继续用解释的方式执行
- 如果到了阈值,则检查该代码是否存在已经编译好的产物
- 如果有编译好的产物直接使用
- 如果没有编译好的产物,则发送编译的请求
- 虚拟机需要对已经编译好的机器码进行缓存
Dalvik上的垃圾回收
垃圾回收是Java虚拟机最为重要的一个特性。垃圾回收使得程序员不用再关心对象的释放问题,极大的简化了开发的过程。在前面的内容中,我们已经介绍了主要的垃圾回收算法。这里我们来具体看一下Dalvik虚拟机上的垃圾回收。
Davlik上的垃圾回收主要是在下面的这些时机会触发:
- 堆中无法再创建对象的时候
- 堆中的内存使用率超过阈值的时候
- 程序通过
Runtime.gc()主动GC的时候 - 在OOM发生之前的时候
不同时机下GC的策略是有区别的,在Heap.h中定义了这四种GC的策略:
// Heap.h
/* Not enough space for an "ordinary" Object to be allocated. */
extern const GcSpec *GC_FOR_MALLOC;
/* Automatic GC triggered by exceeding a heap occupancy threshold. */
extern const GcSpec *GC_CONCURRENT;
/* Explicit GC via Runtime.gc(), VMRuntime.gc(), or SIGUSR1. */
extern const GcSpec *GC_EXPLICIT;
/* Final attempt to reclaim memory before throwing an OOM. */
extern const GcSpec *GC_BEFORE_OOM;
不同的垃圾回收策略会有一些不同的特性,例如:是否只清理应用程序的堆,还是连Zygote的堆也要清理;该垃圾回收算法是否是并行执行的;是否需要对软引用进行处理等。
Dalvik的垃圾回收算法在下面这个文件中实现:
/dalvik/vm/alloc/MarkSweep.h
/dalvik/vm/alloc/MarkSweep.cpp
从文件名称上我们就能看得出,Dalvik使用的是标记清除的垃圾回收算法。
Heap.cpp中的dvmCollectGarbageInternal函数控制了整个垃圾回收过程,其主要过程如下图所示:
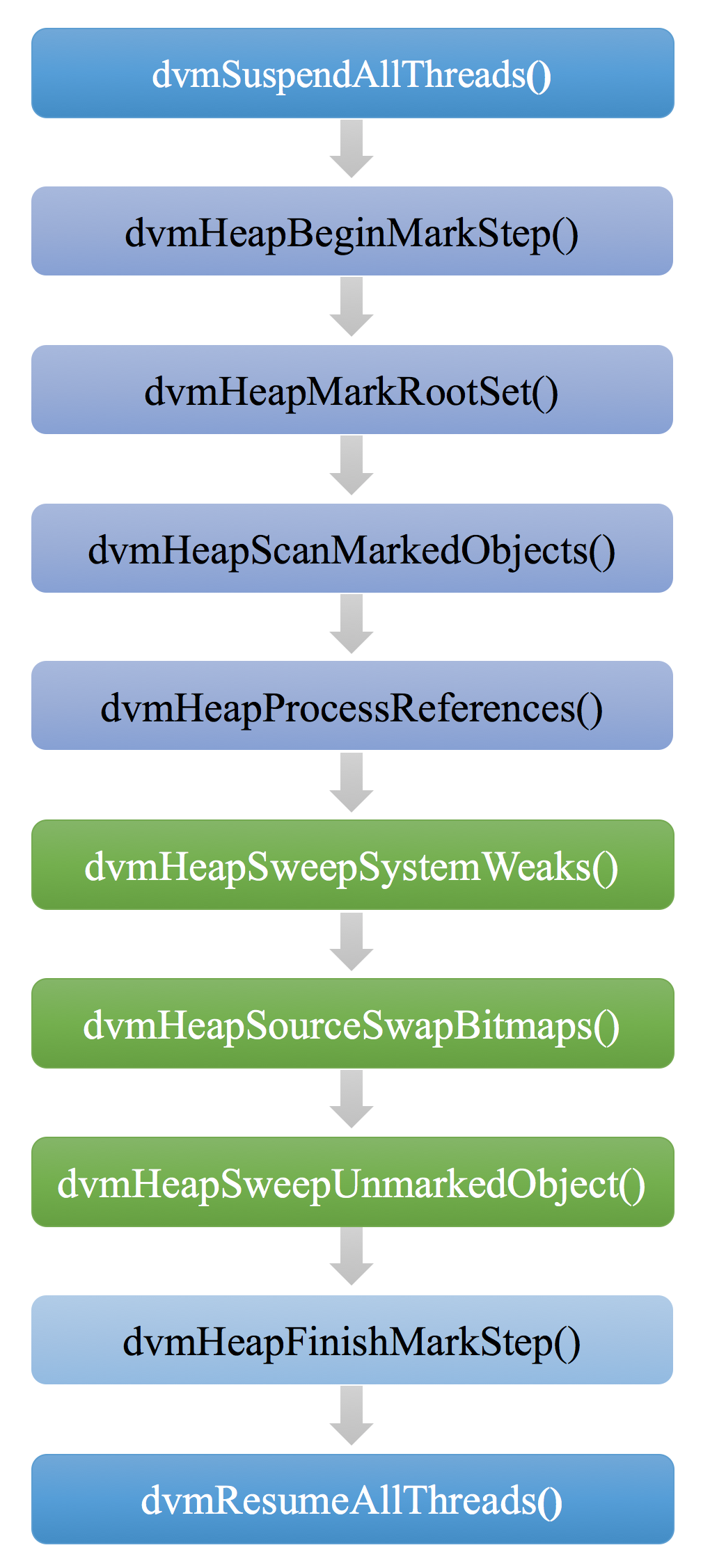
在垃圾收集过程中,Dalvik使用的是对象追踪方法,这其中的详细步骤说明如下:
- 在开始垃圾回收之前,要暂停所有线程的执行:
dvmSuspendAllThreads(SUSPEND_FOR_GC); - 创建GC标记的上下文:
dvmHeapBeginMarkStep - 对GC的根对象进行标记:
dvmHeapMarkRootSet - 然后以此为起点进行对象的追踪:
dvmHeapScanMarkedObjects - 处理引用关系:
dvmHeapProcessReferences - 执行清理:
dvmHeapSweepSystemWeaksdvmHeapSourceSwapBitmapsdvmHeapSweepUnmarkedObjects
- 完成标记工作:
dvmHeapFinishMarkStep - 恢复所有线程的执行:
dvmResumeAllThreads
dvmHeapSweepUnmarkedObjects函数会调用sweepBitmapCallback来清理对象,这个函数的代码如下所示:
// MarkSweep.cpp
static void sweepBitmapCallback(size_t numPtrs, void **ptrs, void *arg)
{
assert(arg != NULL);
SweepContext *ctx = (SweepContext *)arg;
if (ctx->isConcurrent) {
dvmLockHeap();
}
ctx->numBytes += dvmHeapSourceFreeList(numPtrs, ptrs);
ctx->numObjects += numPtrs;
if (ctx->isConcurrent) {
dvmUnlockHeap();
}
}
在上一篇文章中,我们讲过:垃圾回收清理完对象之后会遗留下内存碎片,因此虚拟机还需要对碎片进行整理。在Dalvik虚拟机中,是直接利用了底层内存管理库完成这项工作。Dalvik的内存管理是基于dlmalloc实现的,这是由Doug Lea实现的内存分配器。而Dalvik的内存整理是直接利用了dlmalloc中的mspace_bulk_free函数进行了处理。读者可以在这里了解 dlmalloc 。
看到Dalvik垃圾回收算法的读者应该能够发现,Dalvik虚拟机上的垃圾回收有一个很严重的问题,那就是在进行垃圾回收的时候,会暂停所有线程。而这个在程序执行过程中几乎是不能容忍的,这个暂停会造成应用程序的卡顿,并且这个卡顿会伴随着每次垃圾回收而存在。这也是为什么早期Android系统给大家的感受就是:很卡。这也是Google要用新的虚拟机来彻底替代Dalvik的原因之一。
在下一篇文章中,我们会讲解Android系统上新的虚拟机:ART,也会看到它是如何解决垃圾回收的卡顿问题的。
参考资料与推荐读物
- Dalvik 字节码
- Dalvik 可执行文件格式
- Google I/O 2010 - A JIT Compiler for Android’s Dalvik VM
- Dalvik VM Internals
- Virtual Machine Showdown: Stack Versus Registers
- THE DALVIK VIRTUAL MACHINE ARCHITECTURE
- Dalvik and ART
- A Closer Look At ART in Android L
- Hello, JIT World: The Joy of Simple JITs
- Dalvik虚拟机简要介绍和学习计划