表达式是C++语言的基石。每个表达式都有两个属性:类型(type)和值类别(value category)。前者是大家都熟悉的,但是后者却可能是我们不太在意的。本文的目的是介绍与值类别相关的一些知识。

前言
本文是C++基础系统文章中的一篇,将介绍C++中的值类别,以及与之相关的一些概念。
表达式与值类别
C++的程序由一系列的表达式(expressions)构成。表达式是运算符和操作数的序列,表达式指定一项计算。
例如:2 + 2 或者 std::cout << "Hello World" << std::endl都是表达式。
每个表达式有两个互相独立但是非常重要的属性:
- 类型(type)。类型是我们很熟悉的概念,
int,double和std::string这些都是类型。类型确定了表达式可以进行哪些操作。 - 除了类型之外,还有一个称之为值类别(value category)的属性,却可能是我们平时不太注意的。
type和category在中文中似乎都可以翻译成“类型”。但在本文中,为了区分它们,统一将type翻译成“类型”,category翻译成“类别”。
为什么要懂这些东西?
不管你在不在意,每个表达式都属于三种值类别(prvalue,xvalue,lvalue)中的一种。值类别可以影响表达式的含义,例如:你应该知道这个表达式是没有意义的:3 = 4,它甚至编译不过。但你可能说不出来为什么编译器会认为它编译不过。
如果你使用gcc编译器,它的报错如下:
error: lvalue required as left operand of assignment
这个报错中的lvalue就是数字表达式3的值类别。
再者,值类别还会影响函数的重载:当某个函数有两种重载可用,其中之一接受右值引用的形参而另一个接受 const 的左值引用的形参时,右值将被绑定到右值引用的重载之上。如果你不明白这里提到的“左值引用”和“右值”是指什么的话请不要担心,这就是本文所要说明的。
从左值和右值说起
最初的时候,只有左值(lvalue)和右值(rvalue)这两个术语。它们源于C++的祖先语言:CPL。
lvalue之所以叫lvalue,是因为它常常出现在等号的左边(left-hand side of an assignment)。同样,rvalue是因为它常常出现在等号的右边(right-hand side of an assignment)。
回顾一下上面的3 = 4编译报错,就是因为编译器要求等号的左边得是一个lvalue,而数字3其实是一个rvalue,所以这个是无法通过编译的。
C语言遵循了相似的分类法,但是否需要等号赋值已经不再重要。在C语言中,标识一个对象的表达式称之为左值,不过lvalue已经是“locator value”的简写,因为lvalue对应了一块内存地址。
你可以简单的理解为:左值对应了具有内存地址的对象,而右值仅仅是临时使用的值。例如int a = 1中,a是左值,1是右值。
C++11中的值类别
C++中对于值类别的定义也经历一些变化。从C++11标准开始,值类别早以不止是lvalue和rvalue两种这么简单。
但情况也不算太坏,因为主要的值类别有:lvalue,prvalue 和 xvalue三种。加上两种混合类别:glvalue和rvalue,一共有五种。
我们来看一下它们的定义:
- A glvalue(generalized lvalue) is an expression whose evaluation determines the identity of an object, bit-field, or function.
- A prvalue(pure rvalue) is an expression whose evaluation initializes an object or a bit-field, or computes the value of an operand of an operator, as specified by the context in which it appears, or an expression that has type cv void.
- An xvalue(eXpiring value) is a glvalue that denotes an object or bit-field whose resources can be reused (usually because it is near the end of its lifetime).
- An lvalue is a glvalue that is not an xvalue.
- An rvalue is a prvalue or an xvalue.
这个定义很难理解,就算翻译成中文,也一样不好理解。所以下文会通过一些示例来对它们进行说明。
这五种类别的分类基于表达式的两个特征:
- 是否拥有身份(identity):可以确定表达式是否与另一表达式指代同一实体,例如比较它们所标识的对象或函数的(直接或间接获得的)地址;
- 是否可被移动(具体见下文):移动构造函数、移动赋值运算符或实现了移动语义的其他函数重载能够绑定到这个表达式。
由此,C++11中对于这五种类别定义如下:
- lvalue是指:拥有身份且不可被移动的表达式。
- xvalue是指:拥有身份且可被移动的表达式。
- prvalue是指:不拥有身份且可被移动的表达式。
- glvalue是指:拥有身份的表达式,lvalue和xvalue都是glvalue。
- rvalue是指:可被移动的表达式。prvalue和xvalue都是rvalue。
这么说起来还是有些拗口,不过其实颠来倒去就是两个特征的“是”与“否”,所以通过一个2x2的表格就很容易描述清楚了:
| 拥有身份(glvalue) | 不拥有身份 | |
|---|---|---|
| 可移动(rvalue) | xvalue | prvalue |
| 不可移动 | lvalue | 不存在 |
注:不存在不拥有身份也不可移动的表达式。
我们可以通过下面这个图来记忆五种类别的关系:
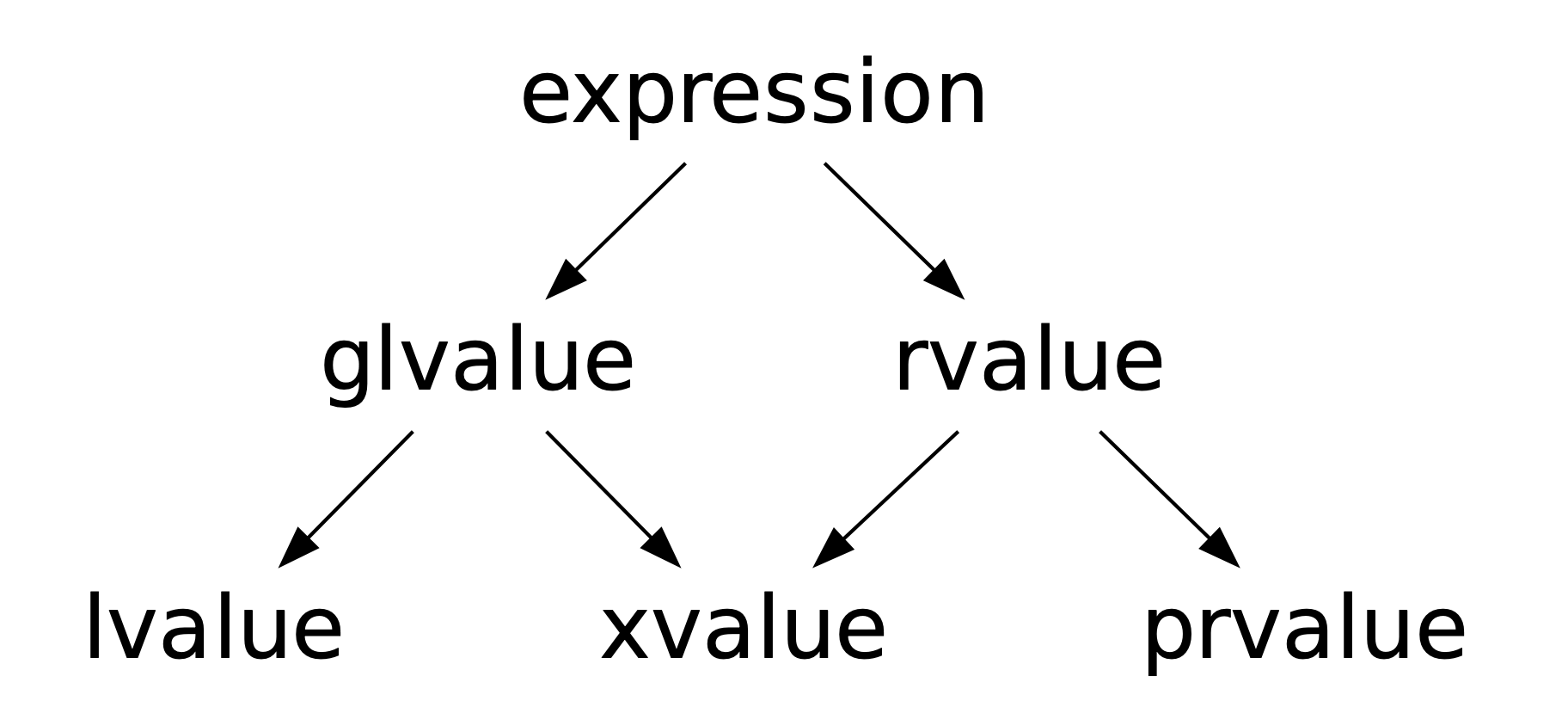
每种值类别都有其关联的性质,这些性质决定了表达式可以如何使用。
glvalue
glvalue是拥有身份的表达式,它对应了一块内存地址。glvalue有lvalue和xvalue两种形式,具体的示例见下文。
glvalue具有以下一些特性:
- glvalue可以自动转换成prvalue。例如:
int a = b,等号右边的lvalue会自动转换成rvalue。 - glvalue可以是多态的(polymorphic),它所对应了动态类型和静态类型可以不一样,例如:一个指向子类的父类指针。
- glvalue可以是不完整类型,只要表达式允许。例如:由前置声明但未定义的类类型。
rvalue
rvalue是指可以移动的表达式。prvalue和xvalue都是rvalue,具体的示例见下文。
rvalue具有以下特征:
- 无法对rvalue进行取地址操作。例如:
&42,&i++,这些表达式没有意义,也编译不过。 - rvalue不能放在赋值或者组合赋值符号的左边,例如:
3 = 5,3 += 5,这些表达式没有意义,也编译不过。 - rvalue可以用来初始化const左值引用(见下文)。例如:
const int& a = 1。 - rvalue可以用来初始化右值引用(见下文)。
- rvalue可以影响函数重载:当被用作函数实参且该函数有两种重载可用,其中之一接受右值引用的形参而另一个接受 const 的左值引用的形参时,右值将被绑定到右值引用的重载之上。
下面是三种具体的值类别:
lvalue
左值是指拥有身份但不可移动的表达式。
变量,函数或者数据成员的名称都是左值表达式。下面是一些左值的例子:
"hello world" // lvalue
int a{}; // lvalue
++a; // lvalue
int& get() {return a;}
get(); // lvalue
int b[4]{}; // lvalue
b[2]; // lvalue
int foo();
int &&a { foo() }; // lvalue
struct foo {int a;};
foo f; // lvalue
f.a; // lvalue
int &&c{ 55 }; // lvalue
int &d{ a }; // lvalue
lvalue具有以下特征:
- 所有glvalue具有的特征
- 可以通过取址运算符获取其地址
- 可修改的左值可用作内建赋值和内建符合赋值运算符的左操作数
- 可以用来初始化左值引用(见下文)
prvalue
prvalue是纯右值,数字字面值或者函数返回的是非引用的值都是prvalue。
下面一些prvalue的例子:
42 // prvalue
true // prvalue
int foo();
foo();// prvalue
int a{}, b{}; // both lvalues
a + b; // prvalue
&a; // prvalue
a++ // prvalue
b-- // prvalue
a && b // prvalue
a < b // prvalue
double {}; // prvalue
std::vector<X> {}; // prvalue
prvalue具有以下特征:
- 所有rvalue具有的特征
- prvalue不会是多态的
- prvalue不会是不完全类型
- prvalue不会是抽象类型或数组
xvalue
xvalue也指向了一个对象,不过这个对象已经接近了生命周期的末尾。这通常和移动语义(见下文)有关。
下面是一些示例:
xvalue与右值引用有很强的关联性,因此看了下文对于右值引用的说明再回过头来看xvalue会更好理解。
bool b {true}; // lvalue
std::move(b); // xvalue
static_cast<bool&&>(b); // xvalue
int&& foo();
foo(); // xvalue
struct foo {int a;};
std::move(f).a; // xvalue
foo{}.a; // xvalue
int a[4]{};
std::move(a); // xvalue
std::move(a)[2]; // xvalue
using arr = int[2];
arr{}[0]; // xvalue
xvalue具有所有rvalue和glvalue所有的特征。
左值引用与右值引用
注意:左值引用和右值引用不属于值类别(value category),它们是表达式的类型(type),并且都是组合类型(compound type)。
我相信每一个C++程序员一定都会知道什么“引用”,但可能并非每个人都知道什么是“右值引用”(rvalue reference)。
在C++11之前,引用分为const引用和非const引用。这两种引用在C++11中都称做左值引用(lvalue reference)。
无法将非const左值引用指向右值。例如,下面这行代码是无法通过编译的:
int& a = 10;
编译器的报错是:
error: non-const lvalue reference to type 'int' cannot bind to a temporary of type 'int'
它的意思是:你无法将一个非const左值引用指向一个临时的值。
但是const类型的左值引用是可以绑定到右值上的,所以下面这行代码是没问题的:
const int& a = 10;
不过,由于这个引用是const的,因此你无法修改其值的内容。
C++11新增了右值引用,左值引用的写法是&,右值引用的写法是&&。
右值是一个临时的值,右值引用是指向右值的引用。右值引用延长了临时值的生命周期,并且允许我们修改其值。
例如:
std::string s1 = "Hello ";
std::string s2 = "world";
std::string&& s_rref = s1 + s2; // the result of s1 + s2 is an rvalue
s_rref += ", my friend"; // I can change the temporary string!
std::cout << s_rref << '\n'; // prints "Hello world, my friend"
在上面这个代码中,s_rref是一个指向临时对象的引用:右值引用。由于这里没有const,因此我们可以借此修改临时对象的内容。
右值引用使得我们可以创建出以此为基础的函数重载,例如:
void func(X& x) {
cout << "lvalue reference version" << endl;
}
void func(X&& x) {
cout << "rvalue reference version" << endl;
}
当传入的参数是一个左值时,会绑定到第一个版本上。当传入的参数是一个右值时,会绑定到第二个版本上,以下面这段代码为例:
X returnX() {
return X();
}
int main(int argc, char** argv) {
X x;
func(x);
func(returnX());
}
其输出是:
lvalue reference version
rvalue reference version
我们整理一下上面的内容:
- 左值引用:即可以绑定到左值(非const),也可以绑定到右值(const)
- 右值引用:只能绑定到右值
右值引用本身是一个左值还是一个右值?答案是:都有可能。右值引用既可能是lvalue,也可能是rvalue。如果它有名称,则是lvalue,否则是rvalue。
右值引用是C++11中两个新增功能的语法基础,这两个功能是:
- 移动语义(Move Semantics)
- 完美转发(Perfect Forward)
下面来逐个介绍。
移动语义
我们知道,在C++中,你可以为类定义拷贝构造函数(copy constructor)和拷贝赋值(copy assignment)运算符。
它们看起来像这样:
class X
{
public:
X(const X& other) // copy constructor
{
m_data = new int[other.m_size];
std::copy(other.m_data, other.m_data + other.m_size, m_data);
m_size = other.m_size;
}
X& operator=(X other) // copy assignment
{
if(this == &other) return *this;
delete[] m_data;
m_data = new int[other.m_size];
std::copy(other.m_data, other.m_data + other.m_size, m_data);
m_size = other.m_size;
return *this;
}
X& operator=(const X& other) // copy assignment
{
if(this == &other) return *this;
delete[] m_data;
m_data = new int[other.m_size];
std::copy(other.m_data, other.m_data + other.m_size, m_data);
m_size = other.m_size;
return *this;
}
private:
int* m_data;
size_t m_size;
};
当然,如果你为类定义了拷贝构造函数和拷贝赋值运算符,你通常还应当为其定义析构函数。这称之为Rule of Three。
拷贝意味着会将原先的数据复制一份新的出来。这么做的好处是:新的数据与原先的数据是独立的两份,修改其中一个不会影响另外一个。但坏处是:这么做会消耗运算时间和存储空间。例如:你有一个包含了$10^{10}$个元素的集合数据,将其拷贝一份就不那么轻松了。
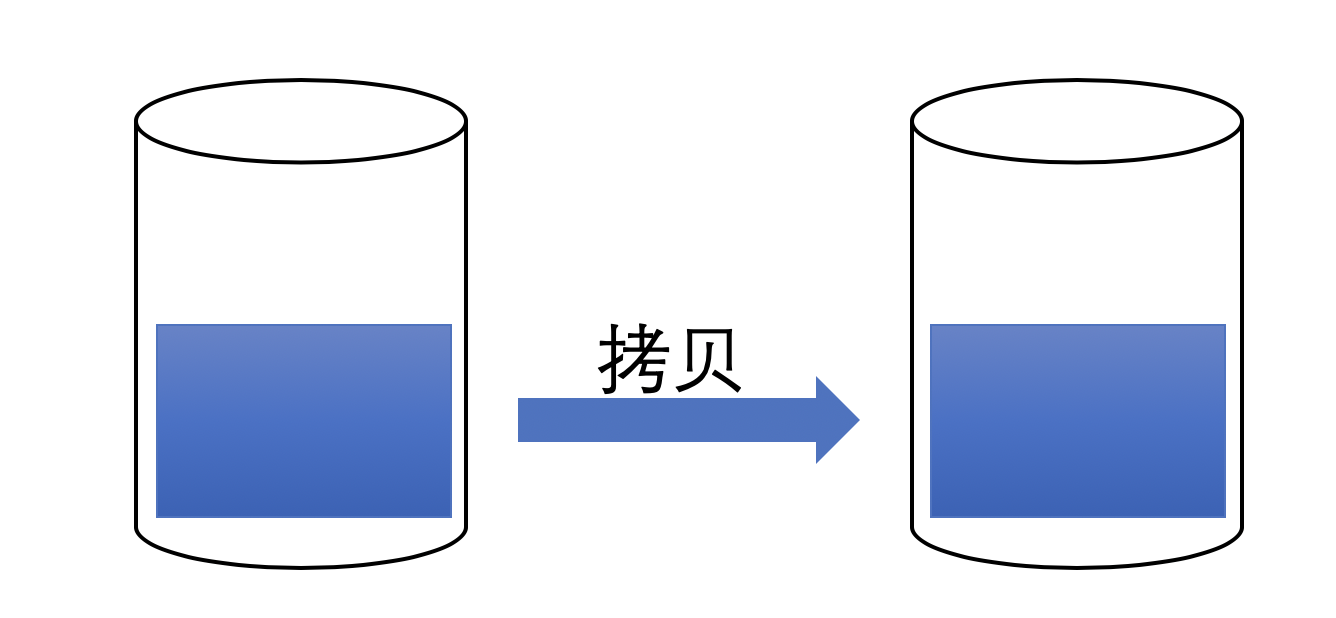
而移动操作则轻量了很多,因为它不涉及新数据的产生,仅仅是将原先的数据更改拥有者。
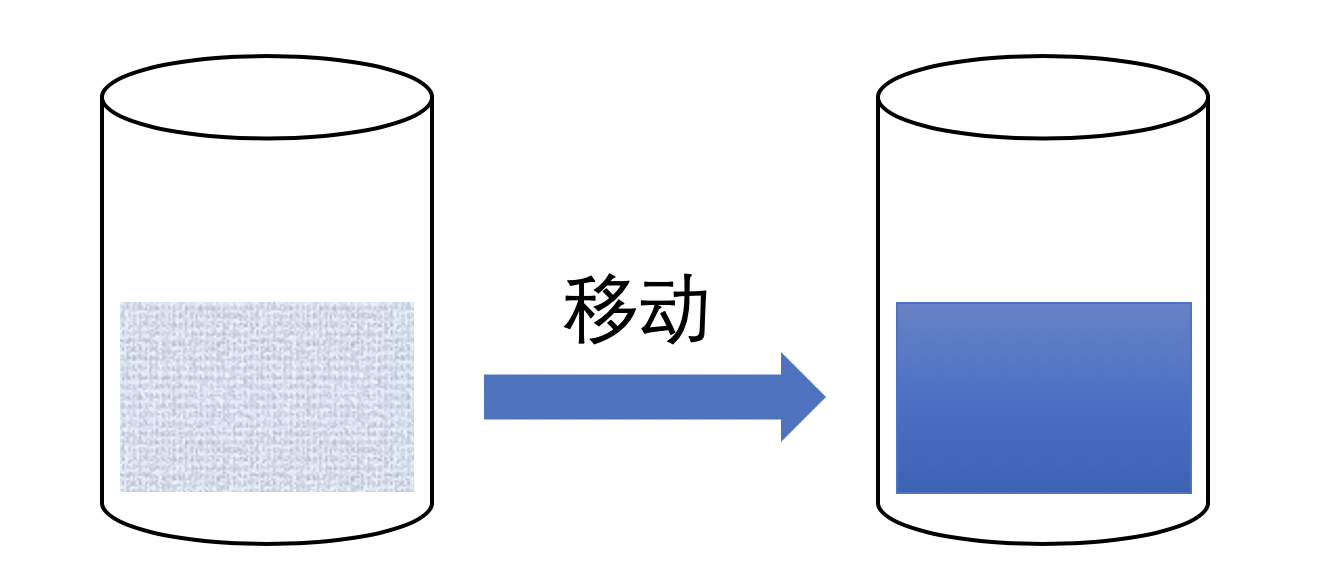
在C++11中,你可以为类定义移动构造函数(move constructor)和移动赋值(move assignment)运算符。它们看起来是这样:
X(X&&);
X& operator=(X&&);
你应该已经看出,这里用到的都是右值引用。
继续以上面定义的类型为例,其移动构造函数和移动赋值运算符的实现可能是这样的:
X(X&& other) // <-- rvalue reference in input
{
m_data = other.m_data; // ①
m_size = other.m_size;
other.m_data = nullptr; // ②
other.m_size = 0;
}
X& operator=(X&& other) // <-- rvalue reference in input
{
if (this == &other) return *this;
delete[] m_data; // ③
m_data = other.m_data; // ④
m_size = other.m_size;
other.m_data = nullptr; // ⑤
other.m_size = 0;
return *this;
}
在这段代码中:
- 获取
other对象所包含的值 - 处理
other的内部结构,防止再次使用 - 释放自身包含的指针
- 获取
other对象所包含的值 - 处理
other的内部结构,防止再次使用
现在,该类有了拷贝和移动两种操作,那编译器如何知道该选择哪个呢?答案是,根据传入的参数类型:如果是左值引用,则使用拷贝操作;如果是右值引用,则使用移动操作。
X createX(int size)
{
return X(size);
}
int main()
{
X h1(1000); // regular constructor
X h2(h1); // copy constructor (lvalue in input)
X h3 = createX(2000); // move constructor (rvalue in input)
h2 = h3; // assignment operator (lvalue in input)
h2 = createX(500); // move assignment operator (rvalue in input)
}
这里的两次移动操作避免了数据复制的资源消耗。
接下来的问题是:如果是左值,也能调用移动操作吗?
答案是肯定的,借助std::move()即可。
std::move()的名称具有一定的迷惑性,因为它并没有进行任何“移动”的操作,它仅仅是:无条件的将实参强制转换成右值引用,仅此而已。因此C++之父认为它的名字叫做rval()应该更合适。但是不管怎么样,由于历史原因,它已经叫做std::move()。
所以,下面这个代码中x2构造时调用的也是移动构造函数:
X x1(1000);
X x2(std::move(x1));
不过需要注意的是,由于x1其中包含的值已经被移动走了,因此你不应当再使用它了。
有了右值引用和移动操作之后,STL中的集合操作变得更加高效了,例如:
std::string str = "Hello";
std::vector<std::string> v;
v.push_back(str); // ①
v.push_back(std::move(str)); // ②
这里的①将复制一个字符串添加到集合中,而②是将已有的对象移动进集合中,因此自然是更高效的。
perfect forward
在C++11之前,C++语言存在一个称之为“The Forwarding Problem”的问题。
这个问题直到C++11才得以解决。不过要说清楚这个问题并不那么容易。下面以一个具体的代码示例来说明。
一直以来,我们都是通过push_back方法往vector中添加对象的:
class MyKlass {
public:
MyKlass(int ii_, float ff_) {...}
...
};
some function {
std::vector<MyKlass> v;
v.push_back(MyKlass(2, 3.14f));
}
但看了上面的内容,你应该已经意识到,这样的方式是通过拷贝的形式完成添加的:要先创建出一个临时对象来,然后拷贝进集合中,这样做效率不够高。更好的方法当时是通过移动。于是C++11为集合类添加了 emplace 和 emplace_back 方法。
emplace_back用起来像这样:
v.emplace_back(2, 3.14f);
这个方法接受模板实例类MyKlass的构造函数形参,这样做避免了临时对象的构造。
但是你有没有想过emplace_back函数是如何实现的呢?我们可以尝试一下。
我们尝试的第一个版本可能是这样:
template <typename T1, typename T2>
void emplace_back(T1 e1, T2 e2) {
func(e1, e2);
}
这个方法存在一个问题,那就是它不支持引用类型。即便func的参数是引用类型的,但是外层emplace_back的参数已经是复制的值。也就说,这里会多一次拷贝。
于是我们第二个版本将改成这样,把外层的参数也改成引用的:
template <typename T1, typename T2>
void emplace_back(T1& e1, T2& e2) {
func(e1, e2);
}
这时又有一个问题:左值引用不能指向右值,所以如果我们这样调用是无法通过编译的:
emplace_back(42, 3.14f);
不过const引用是可以指向右值的,所以解决这个问题的办法就是重载:为每个参数定义const和非const两种类型的引用版本,于是乎成了这样:
template <typename T1, typename T2>
void emplace_back(T1& e1, T2& e2) { func(e1, e2); }
template <typename T1, typename T2>
void emplace_back(const T1& e1, T2& e2) { func(e1, e2); }
template <typename T1, typename T2>
void emplace_back(T1& e1, const T2& e2) { func(e1, e2); }
template <typename T1, typename T2>
void emplace_back(const T1& e1, const T2& e2) { func(e1, e2); }
很显然,你马上就意识好像不太对劲。如果是2个参数,需要定义四个重载的版本。那如果是5个参数呢?需要$2^{5}=32$的版本。如果是10个参数呢???
为了解决这个问题,C++11引入了两个新的机制:
- Reference Collapsing Rules,我不太确定它的正式中文翻译是什么。我们姑且称之为:引用符号折叠规则。
- 特殊类型推导规则,这个与Universal Reference相关。
先说第一个:在C++11中,不存在引用的引用,因此A& &的写法是无法编译的。但在模板类型推导的时候,这是有可能发生的。例如下面这个定义:
template <typename T>
void baz(T t) {
T& k = t;
}
当我们用int&去实例化的时候:
int ii = 4;
baz<int&>(ii);
将T替换成int&,于是k的类型就变成了int& &。甚至于,如果用右值引用int&&代替T的话,k的类型就变成了int&& &。
所以C++标准定了一些规则,在这种情况下,编译器会执行Reference Collapsing Rules,具体的规则如下:
- 如果是
A& &将变成A& - 如果是
A& &&将变成A& - 如果是
A&& &将变成A& - 如果是
A&& &&将变成A&&
简单记忆如下:
- 两个或者三个
&都会变成一个& - 四个
&都会变成两个&
然后我们再说第二个规则:特殊类型推导规则是在特殊的环境下才会产生的推导规则(这好像是一句话废话)。 要理解这个,还需要再借助另外一个术语:Universal Reference,我们可以简称URef。这应该是Scott Meyers(Scott Meyers是世界顶级的C++软件开发技术权威之一,他的《Effective C++》,《More Effective C++》你应该听说过)创造的名词。
关于URef的详细内容可以阅读: Scott Meyers 《Universal References in C++11》。
URef的定义如下:

就是说:只有声明为T&&且T需要推导的情况下,才是URef。例如void f(Widget&& w);,由于不需要推导,所以它不是URef。
但下面这个代码中,由于模板需要推导,所以它是URef:
template<typename T>
void foo(T&&);
如果是URef这种情况,则其具有特殊的推导规则。具体描述如下:
- 如果用类型A的左值初始化URef,则URef会变成左值引用
A& - 如果用类型A的右值初始化URef,则URef会变成右值引用
A&&
这个规则有些奇怪。不过这是C++标准定义,编译器执行的规则,所以我们记住它就好。
除了这两个规则之外,C++还为我们提供了forward函数,该函数有两个重载的版本,定义如下:
template<class T>
T&& forward(typename std::remove_reference<T>::type& t) noexcept {
return static_cast<T&&>(t);
}
template <class T>
T&& forward(typename std::remove_reference<T>::type&& t) noexcept {
return static_cast<T&&>(t);
}
forward函数依赖<type_traits>头文件中的另外一个结构体remove_reference:
template< class T >
struct remove_reference;
remove_reference中包含了一个类型成员名称为type:
template< class T >
using remove_reference_t = typename remove_reference<T>::type;
若类型T为引用类型,则成员type为T所引用的类型。否则type为T本身。例如:
std::remove_reference<int>::type得到intstd::remove_reference<int&>::type依旧得到intstd::remove_reference<int&&>::type仍然得到int
回到forward函数,它借助remove_reference将传入的类型强制转换成对应的T&&形式。
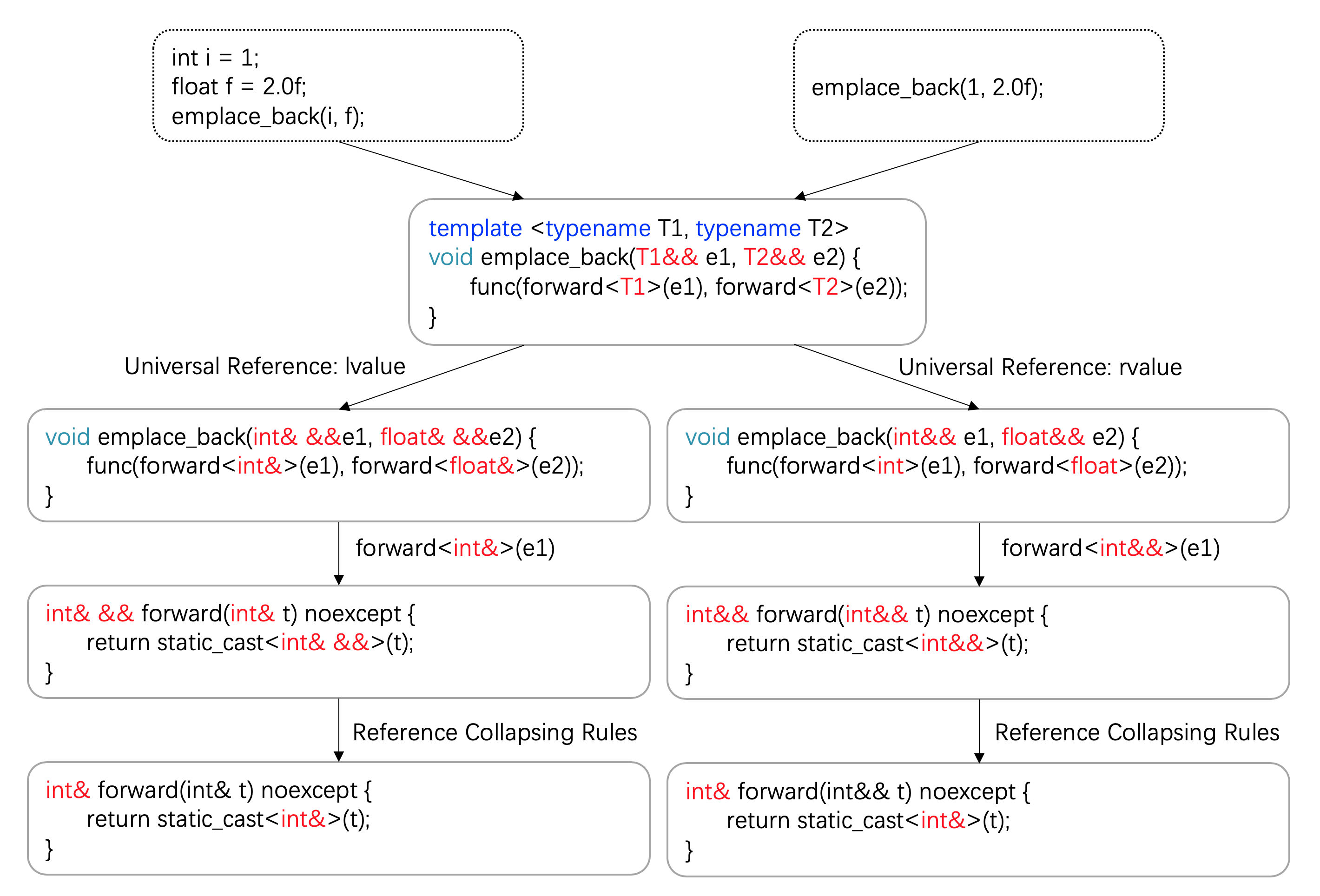
回到我们之前的问题上。我们将emplace_back定义成下面这样:
template <typename T1, typename T2>
void emplace_back(T1&& e1, T2&& e2) {
func(forward<T1>(e1), forward<T2>(e2));
}
第一种情况,当我们通过左值去使用它的时候:
int i = 1;
float f = 2.0f;
emplace_back(i, f);
T替换成int&,emplace_back会变成下面这样:
void emplace_back(int& &&e1, float& &&e2) {
func(forward<int&>(e1), forward<float&>(e2));
}
然后我们选取第一个参数为例(第二个参数是类似的),forward会变成这样:
int& && forward(int& t) noexcept {
return static_cast<int& &&>(t);
}
然后执行引用符号折叠规则,会变成这样:
int& forward(int& t) noexcept {
return static_cast<int&>(t);
}
于是调用成功。
另外一种情况,对于emplace_back(1, 2.0f);调用方式,你可以自行推导一下其变化过程。
这个过程通过语言来描述很啰嗦,所以下面通过一幅图来说明整个过程,也希望帮你对比记忆:
参考资料与推荐读物
- Working Draft, Standard for Programming Language C++
- Effective Modern C++: 42 Specific Ways to Improve Your Use of C++11 and C++14
- cppreference: Value categories
- Understanding lvalues and rvalues in C and C++
- Understanding the meaning of lvalues and rvalues in C++
- C++ rvalue references and move semantics for beginners
- jeaye/value-category-cheatsheet
- A Brief Introduction to Rvalue References
- 《C++ Templates》(2nd)附录B:Value Categories(值类别)
- VALUE CATEGORIES – [L, GL, X, R, PR]VALUES
- C++ and Beyond 2012: Scott Meyers - Universal References in C++11
- The deal with C++14 xvalues
- C++ Rvalue References Explained
- Perfect forwarding and universal references in C++