生活中的很多事情潜在的都符合某种规律。例如:反复抛掷一枚均匀的硬币,出现正面和反面的机会是差不多的;我们认识的人里面特别高或者特别矮的都不多,大部分人的身高都在一个比较接近的范围内。概率论通过概率分布来描述事件出现的频率。本文选取了一些常见的概率分布做一些介绍,以方便在今后使用的时候可以查阅。
当然,“常见”是一个很口语而非科学的说法,因为这很难有明确的标准。如果想要对更多的概率分布做深入研究,请以文末的链接为起点进行更多探索。
基础知识
为了便于描述,这里我们先做一些基础知识的介绍。
随机变量
随机变量是可以随机地取不同值的变量。例如:抛掷一枚硬币,出现正面或者反面的结果;从一个班级中,随机选一个同学,他的身高值。
随机变量可以是离散的或者连续的。离散随机变量拥有有限(例如正面或者反面)或者可数无限多的状态。连续随机变量伴随着实数值(例如:身高)。
概率质量函数
离散型变量的概率分布可以用概率质量函数(Probability Mass Function,简称PMF)来描述。我们通常用大写字母P来表示概率质量函数。
概率密度函数
当研究的对象是连续型随机变量时,我们用概率密度函数(Probability Density Function,简称PDF)来描述它的概率分布。我们通常用小写字母p来描述概率密度函数。
期望
函数 $f(x)$ 关于某分布的期望(Expectation)或者期望值(Expected value)是指:当x由P产生,f作用于x时,$f(x)$的平均值。
对于离散型随机变量,期望值可以通过求和得到:
\[E_{x \sim P[f(x)]} = \sum_xP(x)f(x)\]对于连续型随机变量,期望值可以通过求积分得到:
\[E_{x \sim p[f(x)]} = \int p(x)f(x) dx\]方差与标准差
方差(Variance)衡量的是当我们对x依据它的概率分布进行采样时,随机变量x的函数值会呈现多大的差异。
计算方差的函数如下:
\[Var(f(x)) = E[(f(x)-E[f(x)])^2]\]方差的平方根称之为标准差(Standard Deviation)。有些资料也称标准差为均方差。
一幅图理解期望和方差
台湾大学李毅宏教授的这节课程: 《Where does the error come from?》 仅仅通过一幅图就非常好的解释了期望和方差的概念。
结果与期望的偏离称之为偏差(Bias)。通俗的讲,Bias描述了结果与中心的偏离程度。而方差(Variance)描述了结果互相之间的散列程度。
你可以对比下面这幅图的四种情况来加深理解:
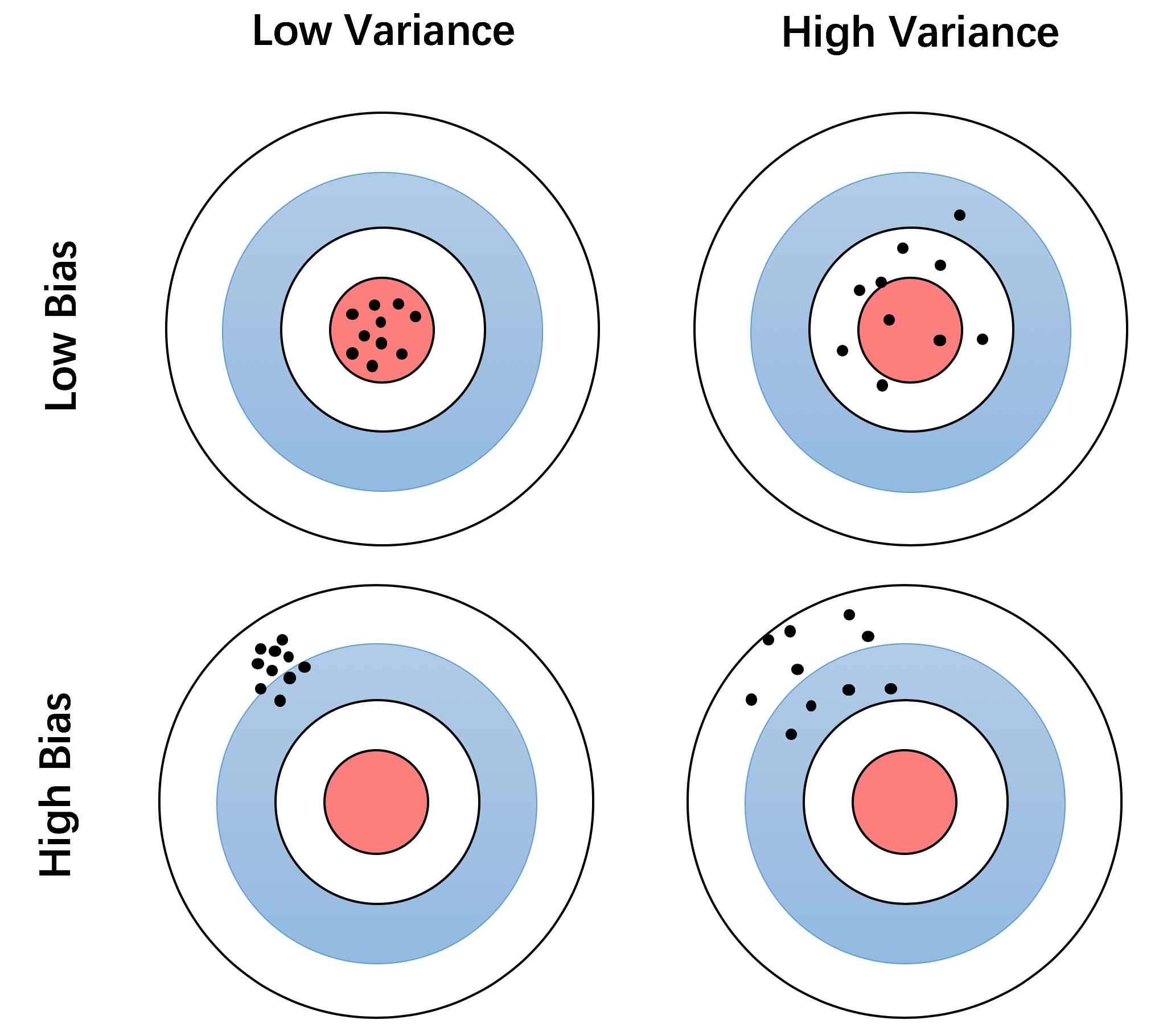
从这幅图中我们可以看出:
- 当Bias和Variance都比较小的时候,结果都比较紧密的集中在预期的值上。
- 当Bias较小而Variance较大时,意味着结果较靠近预期,但是比较散落。
- 当Bias较大而Variance较小时,意味着结果集中在一起,但是离预期值偏离较多。
- 当Bias和Variance都较大时,意味着结果既不靠近预期,也比较散落。
李毅宏教授的课程是我目前发现的最好的机器学习资料,他的授课把那些复杂的概念,解释的非常的清晰和通俗。
因此强烈推荐给大家。
李毅宏教授的个人网站:李宏毅 (Hung-yi Lee)
李毅宏教授的Youtube站点:Youtube:李宏毅
离散型分布
伯努利分布
伯努利(Bernoulli)分布是最基本,也是我们最常见的分布。这个名称是为了纪念瑞士科学家雅各布·伯努利(Jakob I. Bernoulli)而命名。
伯努利分布在生活中非常的常见。例如,抛掷一枚硬币的结果就是符合伯努利分布的:结果只会是正面或者反面。
下文将看到,好几种其他的分布都与伯努利分布有一定的关系。
伯努利分布亦称“零一分布”、“两点分布”:它的结果只会是两种可能性中的一种,且这两种结果互相对立,必居其一。因此,我们也常常称结果是成功的,或者失败的。
假设伯努利实验成功的概率是p,则伯努利分布的概率质量函数如下:
当然,考虑到X只有0和1两种可能,我们也可以直接写成:
\[P(X=x) = \begin{cases} p\;(x=1) \\ 1-p\;(x=0) \end{cases}\]伯努利分布的期望值是 p,方差是 $p(1-p)$。
二项分布
我们可以很自然的可以将一次伯努利实验扩展到多次,此时其结果符合二项(Binomial)分布。
二项分布的概率质量函数如下:
\[P(X=k) = \binom{n}{k}p^{k}(1-p)^{n-k}\]这里的:
\[\binom{n}{k} = \frac{n!}{k!(n-k)!}\]通过这个函数,我们可以计算出在进行n次的伯努利实验中,有k次出现正面结果的概率。
很显然,当n为1时,这个函数和伯努利的概率质量函数是一样的。
二项分布的期望值是np,方差是$np(1-p)$。
几何分布
几何(Geometric)分布也是进行多次的伯努利实验。
它指的是:在n次伯努利试验中,试验k次才得到第一次成功的机率。或者说,就是:前k-1次皆失败,第k次成功的概率。
几何分布的概率质量函数如下:
\[P(X = k) = p(1-p)^{k - 1}\]几何分布的期望是$\frac{1}{p}$,方差是$\frac{(1-p)}{p^2}$。
多项分布
进一步的,我们可以将二项分布扩展到多项(Multinomial)分布。
多项分布的结果有超过2种的更多种情况。例如:抛掷一枚骰子,其结果可能是1~6中的某个数值。
假设有$X_1$到$X_k$种结果,每种结果发生的概率是$p_1$到$p_k$,多项分布的概率质量函数如下:
\[P(X_1=n_1,...,X_k=n_k) = \frac{n !}{n_1! ... n_k !} p_1^{n_1} ... p_k^{n_{k}} , \; (\sum_{i=1}^k x_{i} = n)\]对于每个$X_{i}$来说,其数学期望是 $E(X_{i}) = np_{i}$,其方差是 $Var(X_{i}) = np_{i}(1-p_{i})$。
离散均匀分布
特别地,当我们仅仅进行一次多项实验,并且多项的各项结果是等可能的,那么这个时候就得到的就是离散均匀(Discrete Uniform)分布。
其概率密度函数如下:
\[P(X = x) = \frac{1}{N} \; (x= 1,...,N)\]例如,抛掷一枚均匀的骰子,出现6个数中任意一个的概率都是 $\frac{1}{6}$。
离散均匀分布的期望值是 $\frac{N+1}{2}$,方差是 $\frac{(N+1)(N-1)}{12} $。
很显然,上面几种分布都与伯努利分布存在一定的关系,下面这幅图描述了它们之间的关系:
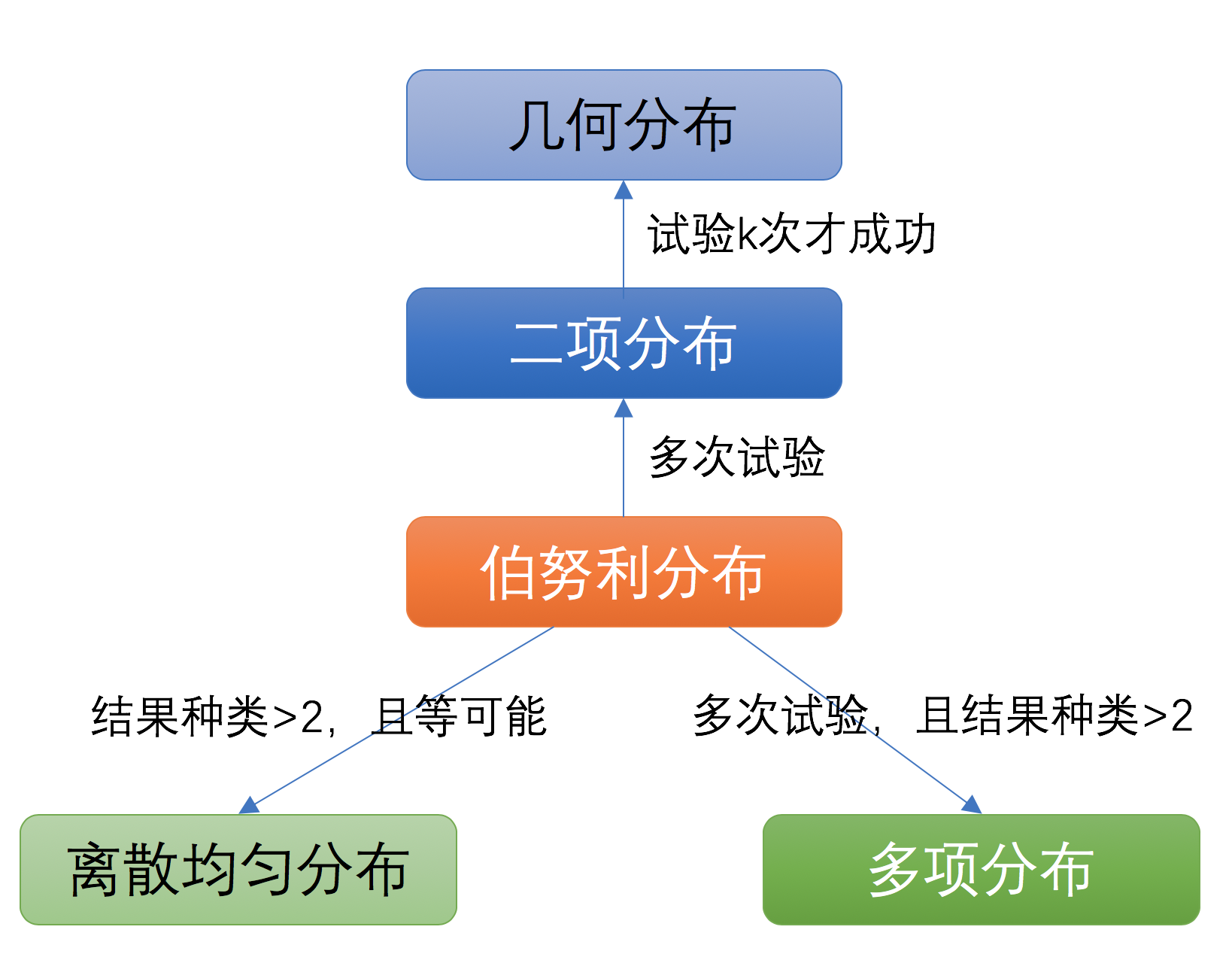
泊松分布
泊松(Poisson)分布是另外一种很常见的概率分布,由法国数学家西莫恩·德尼·泊松(Siméon-Denis Poisson)在1838年时发表。
我们可以回想一下,生活中很多事情都以特定频率的反复发生的,例如:
- 某个医院平均每天有100个新生儿;
- 某个客服号码每个小时会接到50个来电;
- 某一班公交每个小时会5次经过其中一个站点;
- 等等等等;
过去发生的平均频度我们是可以计算的,但是我们永远无法精确计算该事件下一次发生的时间点。
泊松分布描述的是:在已知过去发生频率的基础上,预测在接下来一段特定的时间内,该事件发生特定次数的概率。
这么说有些拗口,但是接下来我们通过一个具体的例子就很容易理解了。
泊松分布的概率质量函数如下:
\[P(k) = \frac{e^{-\lambda}\lambda^{k}}{k!} \; ,\lambda \ge 0\]这里的e是一个常量,约等于2.71828。$\lambda$是过去单位时间内发生的频率,k是预测发生的次数。
以公交为例,假设我们知道过去它每个小时平均会5次经过其中一个站点($\lambda$=5),那么接下来的一个小时,它经过的次数很可能是4~6次。不太可能是1次或者10次。我们可以根据概率质量函数,计算它接下来一个小时分别经过1次,4次,5次,10次的概率。
-
当k=1时:$P(1) = \frac{e^{-5}5^{1}}{1!} \approx 0.034 $
-
当k=4时:$P(4) = \frac{e^{-5}5^{4}}{4!} \approx 0.175 $
-
当k=5时:$P(5) = \frac{e^{-5}5^{5}}{5!} \approx 0.175 $
-
当k=10时:$P(10) = \frac{e^{-5}5^{10}}{10!} \approx 0.018 $
当然,我们不用自己手算,借助于Python的scipy.stats库可以很轻松的计算出结果。
Python的scipy.stats库包含了许多种分布的许多相关函数。
借助于matplotlib,我们甚至可以很轻松的将这个结果以图形的方式展示出来。
下面这段代码,绘制了上面我们想要的结果:
import matplotlib.pyplot as plt
import numpy as np
from scipy.stats import poisson
x = np.arange(0, 11)
lamda = 5
plt.bar(x, poisson.pmf(x, lamda))
plt.text(8, 0.17, 'lamda=5')
plt.title('Poisson Distribution')
plt.show()
这段代码很简单,这里就不多做说明了。 网上有很多关于numpy和matplotlib的教程,也可以看我之前写的文章:
另外,这篇文章也很值得一看:Plotting Distributions with matplotlib and scipy。
下面这幅图就是我们得到的结果。可以看到,这和我们前面计算的结果是一致的。
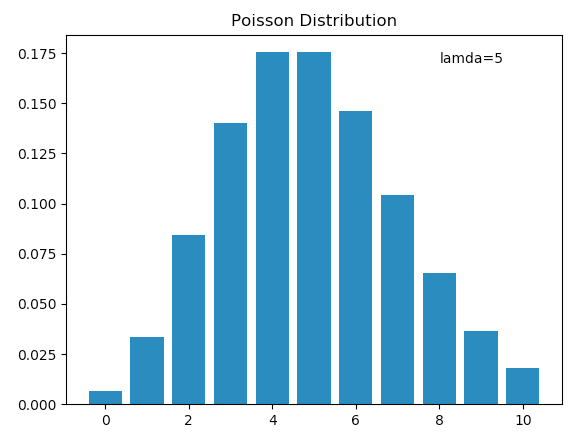
泊松分布的期望值和方差都是$\lambda$。
连续性分布
高斯分布
高斯(Gaussian)分布又称正态(Normal)分布。这个概念是由德国的数学家和天文学家Moivre于1733年首次提出的,但由于德国数学家高斯率先将其应用于天文学家研究,故正态分布又叫高斯分布。
高斯分布的概率密度函数曲线呈钟形,因此人们又经常称之为钟形曲线。借助于前面提到的几个库,我们可以很轻松的画出高斯分布的概率密度函数和累积分布函数。
相关代码如下:
import matplotlib.pyplot as plt
import numpy as np
from scipy.stats import norm
x = np.linspace(-3, 3, 1000)
plt.plot(x, norm.pdf(x), label='Probability density function')
plt.plot(x, norm.cdf(x), label='Cumulative distribution function')
plt.legend()
plt.title('Gaussian Distribution')
plt.show()
得到的图形如下:
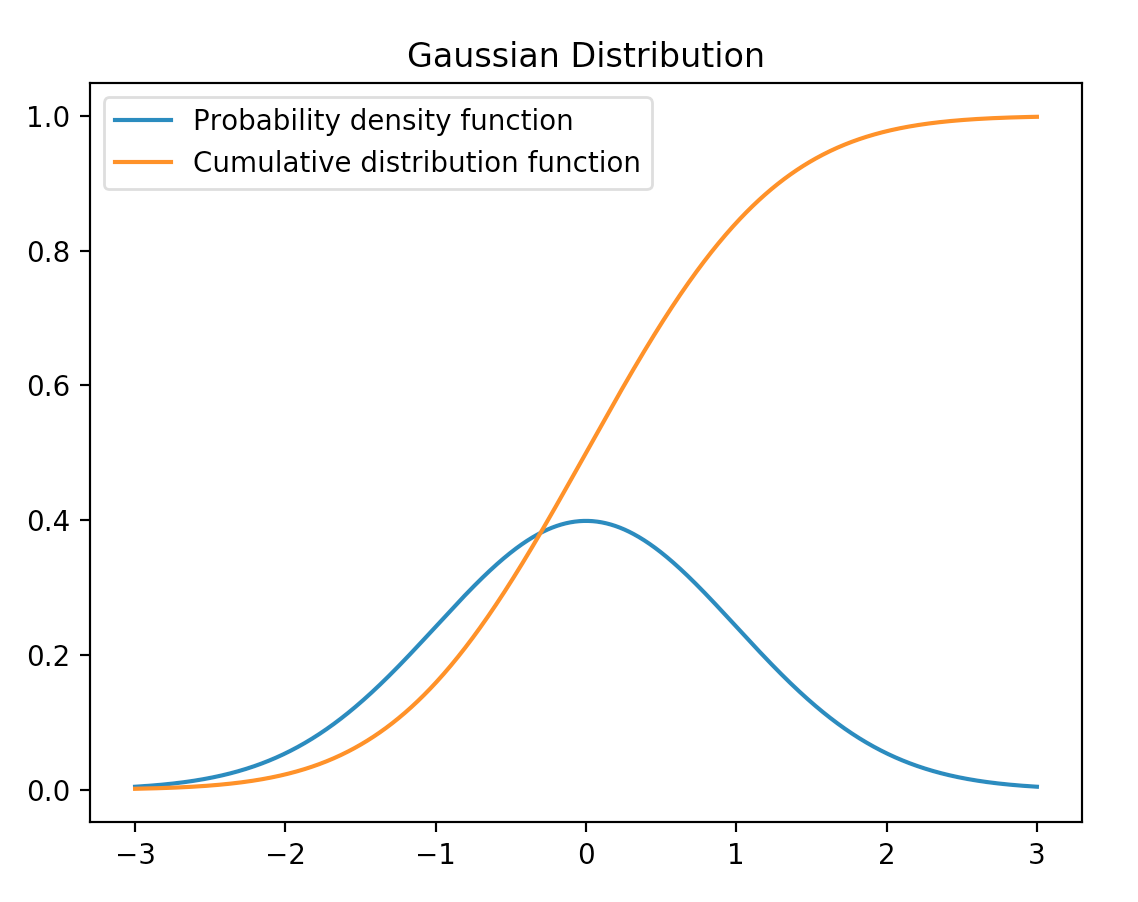
从这个图中我们可以看出,对于高斯分布来说,随机变量处于中间的概率是比较大的,而其取非常大或者非常小的值的概率都很小。我们现实中人们的身高,体重,收入等特点都符合这个模型。
高斯分布的概率密度函数如下:
\[f(x) = \frac{1}{\sqrt{2 \pi}\sigma}e^{-\frac{(x - \mu)^2}{2\sigma^2}}\]对于符合高斯分布的随机变量,我们也经常记做下面这样:
\[X \sim N(\mu, \sigma^2)\]在这个函数中,$\mu$决定了高斯分布的中心位置,$\sigma$决定了钟型曲线的胖瘦程度。实际上,$\mu$就是高斯分布的期望,而$\sigma^2$就是方差。
当 $\mu$ = 0,$\sigma$ = 1时的,我们称之为标准正态分布。
上面我们看到的这个图形就是标准正态分布。
均匀分布
均匀(Uniform)分布要简单很多,它指的就是:随机变量在某个区间内,取任意一个值都是等可能的。
其概率密度函数如下:
\[f(x) = \frac{1}{b-a} , a \le x \le b\]很显然,如果我们将这个函数画成图形,那就是两个区间之间的一个水平线。
均匀分布的期望值是 $\frac{b+a}{2}$,方差是 $\frac{(b-a)^2}{12}$。
指数分布
指数(Exponential)分布是描述泊松过程中的事件之间的时间的概率分布,即事件以恒定平均速率连续且独立地发生的过程。
指数分布的概率密度函数如下:
\[f(x) = \frac{1}{\lambda}e^{-\frac{x}{\lambda}} \; ,x \ge 0, \lambda \gt 0\]指数分布的期望是$\lambda$,方差是$\lambda^2$。
我们仍然是以前面提到的公交车为例。假设每个小时某班公交平均有5次会经过其中一个站点。
则可以通过下面这段代码绘制出其概率密度函数和分布累积函数:
import matplotlib.pyplot as plt
import numpy as np
from scipy.stats import expon
x = np.linspace(0, 1, 1000)
lamda = 5
scale = 1/lamda
plt.plot(x, expon.pdf(x, scale=scale), label='Probability density function')
plt.plot(x, expon.cdf(x, scale=scale), label='Cumulative distribution function')
x1 = 0.2
x2 = 0.4
x3 = 1
y1 = expon.cdf(x1, scale=scale)
y2 = expon.cdf(x2, scale=scale)
y3 = expon.cdf(x3, scale=scale)
plt.scatter([x1, x2, x3], [y1, y2, y3], c="b")
plt.annotate("{:.3f}".format(y1), (x1, y1 + 0.2))
plt.annotate("{:.3f}".format(y2), (x2, y2 + 0.2))
plt.annotate("{:.3f}".format(y3), (x3, y3 + 0.2))
plt.legend()
plt.title('Exponential Distribution')
plt.show()
这段代码得到的图形如下:
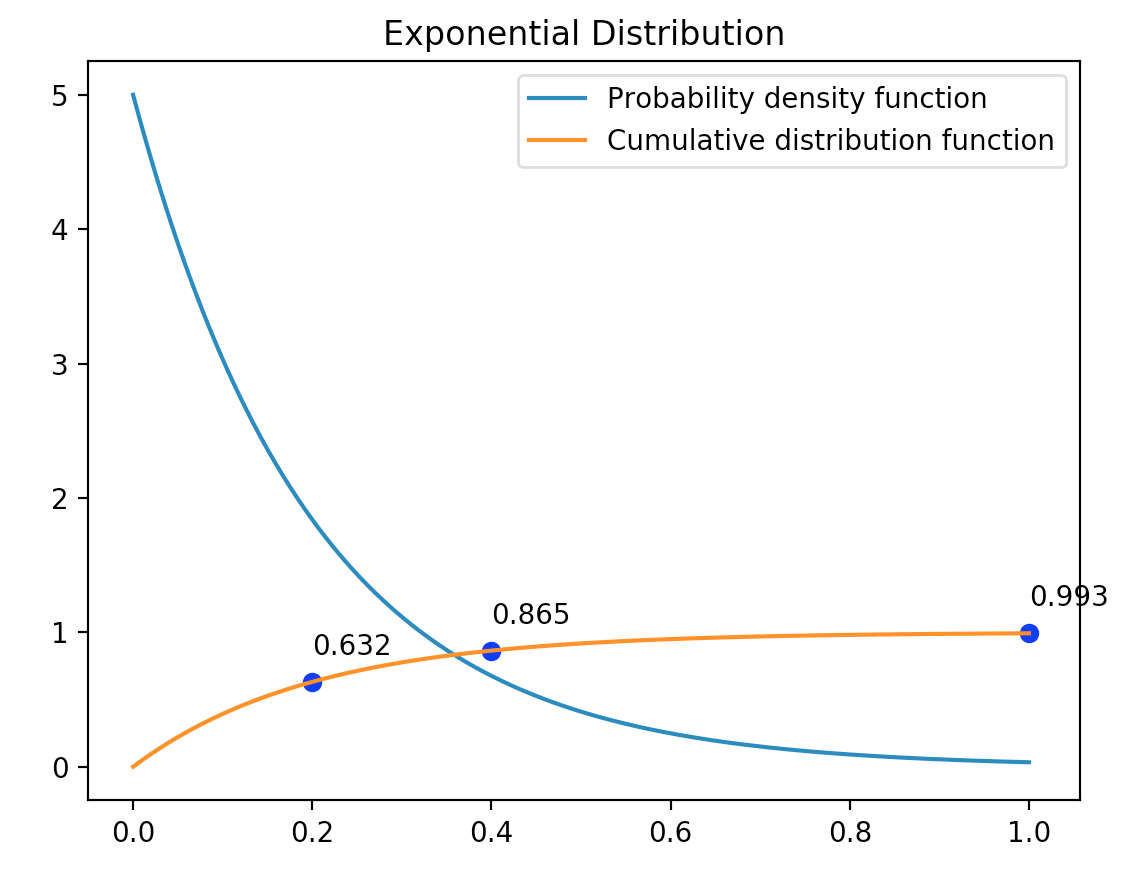
在这段代码中,我们特意的在0.2,0.4和1.0这三个点上做了标记。
从这个图形中我们可以看出,对于这班公交来说,12分钟(0.2小时)来车的概率是0.632,24分钟(0.4小时)来车的概率是0.865。 当等待的时间越接近一个小时,新的一班车就几乎肯定要来了。
结束语
这里我们选取了一些常见的概率分布介绍给大家。这些分布可能是我们在做机器学习时会用到的。
文章的开头也提到,“常见”是一个没有标准的定义,也许后面我还会继续扩充这篇文章,加入更多的内容。
如果你觉得有什么很合适加入的内容,也可以给我留言。
参考资料与推荐读物
- Wikipedia: List of probability distributions
- 《Deep Learning》: Chapter 3
- 《Pattern Recognition and Machine Learning》: Appendix B
- 李宏毅:ML Lecture 2: Where does the error come from?
- Common Probability Distributions: The Data Scientist’s Crib Sheet
- D. Joyce, Clark University: Common probability distributions
- Casella and Berger: Table of Common Distributions
- Scott Oser: Common Probability Distributions
- Plotting Distributions with matplotlib and scipy