本文是一篇关于Python基础知识的文章,介绍Python中最常用的内建数据类型。

前言
越来越多的人使用Python语言,其实很多Python程序员都有C/C++或者Java的编程背景。
不同的编程语言会有很多相似的概念,例如:分支语句,变量,函数,类等。另一方面,不同的编程语言之间也会有很多微妙的差别。例如:是强类型还是弱类型,是否支持垃圾回收等。
除此之外,每种编程语言自带的数据类型也是一种很强烈的语言特征。
为了和大家一起尽可能少的被语言的底层细节干扰,因此接下来会有一些关于Python基础知识的文章。
本文作为开始,会讲解Python中内建数据类型的知识。当然,本文不打算取代Python官方文档或者是其他更加详尽的技术书籍。本文的目的是帮忙读者快速梳理这方面知识。并罗列出核心内容。
从2020年开始,Python 2将逐渐退出历史舞台。因此我们的系列文章仅仅提及Python 3,不会提及Python 2中的语法。
数据类型概述
从分解的角度来看,Python的程序由模块构成,模块由语句构成,语句由表达式构成,表达式创建并处理对象。由此可以看到,对象是程序的最基本组成单元,而对象是类型的实例。
Python中包含了大量的数据类型(其他编程语言,例如Java,C++也是一样)。但其中有一些最为大家所频繁使用的就是内建数据类型。正如其名称所示,这些类型是内置在语言中的,不需要额外的库或者依赖。在满足要求的情况下,使用内建类型是比较好的选择。
本文涉及的类型如下表所示:
| 类型名称 | 英文 |
|---|---|
| 数字 | Number |
| 字符串 | String |
| 列表 | List |
| 字典 | Dictionary |
| 元祖 | Tuple |
| 集合 | Set |
每种类型都有特定适用的场景。根据是否可变,可以将这些类型分为下面两类:
- 可变类型:列表,字典,集合
- 不可变类型:数字,字符串,元祖
对于可变类型,你可以原地修改它们。但对于不可变类型来说,如果你想要修改它们,只能创建它们的拷贝。
除了通过类名的方式来构建对象,下面几种括号是创建这些对象的更简洁的方法:
(...):元组[...]:列表{...}:字典,集合
数值类型
Python中的数值类型并非一种类型,而是一系列类型,它们如下表所示:
| 类型 | 类名 | 说明 |
|---|---|---|
| 整数类型 | int | 包括正整数,负整数和零 |
| 浮点类型 | float | 带有小数部分的数字 |
| 布尔值类型 | bool | 包含True和False两个状态 |
| 复数类型 | complex | 通常在工程和科学应用中使用,包含实部和虚部 |
| 小数类型 | decimal.Decimal | 精度固定的浮点数 |
| 分数类型 | fractions.Fraction | 保持了分子和分母两个部分,避免了浮点运算的不精确 |
整数,浮点数和布尔值类型是大家都比较熟悉的,自然不用多说。而后面三种类型大家可能用的不多。这里稍加介绍:
- 复数带有实部和虚部两个部分,虚部的表示是数字和
j或者J作为后缀。例如:2 + 1j。 - 小数是精度固定的浮点数,小数通过字符串来初始化,例如:
Decimal('0.00001')。 - 分数的实现保留了分子和分母两个部分。这样做的好处是避免了浮点运算的不精确性,坏处是性能较差(相对于浮点数)。
数值字面值
我们通常通过数值字面值来初始化数值类型。下面是一些示例:
from decimal import Decimal
from fractions import Fraction
int_number = 1234
float_number = 0.1234
bool_number = True
complex_number = 3 + 4j
decimal_number = Decimal('0.1') + Decimal('0.2')
fraction_numer = Fraction(1, 3)
print(int_number, type(int_number))
print(float_number, type(float_number))
print(bool_number, type(bool_number))
print(complex_number, type(complex_number))
print(decimal_number, type(decimal_number))
print(fraction_numer, type(fraction_numer))
该代码输出如下:
(1234, <type 'int'>)
(0.1234, <type 'float'>)
(True, <type 'bool'>)
((3+4j), <type 'complex'>)
(Decimal('0.3'), <class 'decimal.Decimal'>)
(Fraction(1, 3), <class 'fractions.Fraction'>)
进制与转换
对于拥有十个手指的人类来说,10进制是最自然的。但对于计算机来说,二进制,八进制和十六进制也非常常用。
在Python中:
0b或者0B作为前缀表示二进制,后面允许的数字是:0,10o或者0O作为前缀表示八进制,后面允许的数字是:0-70x或者0X作为前缀表示十六进制,后面允许的数字是:0-9和a-f或A-F
需要注意的是,不同进制仅仅是书写的不同,作为数值时,用什么进制来书写并没有什么区别。在输出的时候,Python默认是使用十进制实现。
不过Python提供了bin、oct和hex三个函数将数值转换成二进制,八进制和十六进制的字符串。
a = 0b111
b = 0o127
c = 0xAb
print('a =', a, 'bin:', bin(a), 'oct:', oct(a), 'hex:', hex(a))
print('b =', b, 'bin:', bin(b), 'oct:', oct(b), 'hex:', hex(b))
print('c =', c, 'bin:', bin(c), 'oct:', oct(c), 'hex:', hex(c))
其输出如下:
a = 7 bin: 0b111 oct: 0o7 hex: 0x7
b = 87 bin: 0b1010111 oct: 0o127 hex: 0x57
c = 171 bin: 0b10101011 oct: 0o253 hex: 0xab
运算
与数值类型相关的是一系列的运算。运算涉及函数和运算符。函数包含pow,abs等,这类函数非常的多,甚至还有很多第三方的开源科学计算库,本文不打算在这方面过多说明,大家可以在网上自行搜索文档。
这里仅列出数值类型常见的运算符,它们如下表所示:
| 运算符 | 说明 |
|---|---|
| x if y else z | 三元选择表达式 |
| x or y | 逻辑或 |
| x and y | 逻辑与 |
| not x | 逻辑非 |
| x in y, x not in y | 成员关系,是否存在 |
| x is y, x is not y | 同一性测试,是否相同 |
| x < y, x <= y, x > y, x >= y | 大小比较 |
| x == y, x != y | 值等价性判断 |
| x | y | 按位或,集合并集 |
| x ^ y | 按位异或,集合对称差集 |
| x & y | 按位与,集合交集 |
| ~x | 按位非 |
| x « y, x » y | 左移和右移操作 |
| x + y, x - y, x * y | 加法,减法,乘法 |
| x % y | 求余数 |
| x / y, x // y | 真除法和向下取整除法 |
| -x, +x | 取负,取正 |
| x ** y | 幂运算 |
链式比较
判断一个数字是否在某个区间内是一个非常常见的操作。在其他语言中,这通常需要两个比较式并求与来完成。但在Python中,只需要一个表达式即可以完成。因为它支持链式比较。
例如,判断数字是否在[1, 100]区间内:
a = 55
b = 101
print('1 <= a <= 100: ', 1 <= a <= 100)
print('1 <= b <= 100: ', 1 <= b <= 100)
这段代码输出如下:
1 <= a <= 100: True
1 <= b <= 100: False
链式比较可以很长,例如:5 > 4 > 3 > 2 > 1。很显然,链式比较要比多个比较式求与要简洁很多。
除法
如果你有C/C++或者Java语言的编程经验,你会知道,在这些语言中,两个整数相除,其结果仍然是整数,小数部分会被丢弃。这称之为向下取整除法。
在Python中,向下取整除法并非/符号,而是//符号。在Python 3中,/除法会保留小数部分,这称之为:“真除法”。
a = 100
b = 3
print(a, '/', b, '=', a / b)
print(a, '//', b, '=', a // b)
其输出如下:
100 / 3 = 33.333333333333336
100 // 3 = 33
对于从其他语言转向Python语言的一定要注意这些细节差异,因为一个数值的差别可能导致整个程序运转出错。
字符串
要说编程中最常用的数据类型,除了数字类型之外就一定是字符串类型了。
Python没有单个字符的数据类型,只有包含一系列字符的字符串类型。
希望读者知道,单就字符串本身其实就是一个非常大的话题,由于篇幅所限,本文仅能提及最基本的内容。
字符串字面值
大部分时候我们都会通过字面值来初始化字符串。Python提供了多种字面值的表达方法。
- 单引号:
'simple string' - 双引号:
"It's a tiger" - 三引号:
'''...content...''',"""...content...""" - 原始字符串格式:
r"C:\folder\file.txt" - 字节字面值
- Unicode字面值
在Python中,单引号和双引号来表达字符串是一样的含义,因此'string content'和"string content"的值是相等的。另外,在单引号中可以使用双引号,双引号中也可以使用单引号。
a = 'string content'
b = "string content"
c = 'He says "hello"'
d = "It's a nice day."
print(a == b)
print(c)
print(d)
输出:
True
He says "hello"
It's a nice day.
三引号用来包含多行文本。因此其中可以包含换行符。例如:
'''
STAR
WARS
A long time ago in a galaxy far,
far away...
'''
这种写法在想要注释掉多行代码时可能很有用。
最后,原始字符串格式,使得我们不用再对特殊字符转义。这在字符串中包含很多反斜杠时(例如:Windows文件路径时)会很有用。
字符串的方法
如果你查阅Python的文档:String Methods ,就会发现字符串类型包含了非常多的方法。
这里仅列出这些方法,对于它们的详细说明请参阅官方文档。其实很多时候,通过方法名称我们已经可以想到方法的作用。
请注意,字符阿是不可变类型,那些试图“修改”字符串内容的方法其实是返回了一个新的拷贝。
str.capitalize()
str.casefold()
str.center(width[, fillchar])
str.count(sub[, start[, end]])
str.encode(encoding="utf-8", errors="strict")
str.endswith(suffix[, start[, end]])
str.expandtabs(tabsize=8)
str.find(sub[, start[, end]])
str.format(*args, **kwargs)
str.format_map(mapping)
str.index(sub[, start[, end]])
str.isalnum()
str.isalpha()
str.isascii()
str.isdecimal()
str.isdigit()
str.isidentifier()
str.islower()
str.isnumeric()
str.isprintable()
str.isspace()
str.istitle()
str.isupper()
str.join(iterable)
str.ljust(width[, fillchar])
str.lower()
str.lstrip([chars])
static str.maketrans(x[, y[, z]])
str.partition(sep)
str.replace(old, new[, count])
str.rfind(sub[, start[, end]])
str.rindex(sub[, start[, end]])
str.rjust(width[, fillchar])
str.rpartition(sep)
str.rsplit(sep=None, maxsplit=-1)
str.rstrip([chars])
str.split(sep=None, maxsplit=-1)
str.splitlines([keepends])
str.startswith(prefix[, start[, end]])
str.strip([chars])
str.swapcase()
str.title()
str.translate(table)
str.upper()
str.zfill(width)
格式化
我们常常需要按照特定的格式拼接字符串,这就是字符串格式化的用武之地。
Python中下面两种格式化写法都很常用:
- %形式:
'...%s... % (values) - format方法:
'...{}...'.format(values)
第一种写法是将格式化模板与待替换的字符串通过%连接。例如:
template = 'Star.Wars.Episode.%d.%s.%d'
year = 1999
print(template % (1, 'The.Phantom.Menace', year))
它将输出:
Star.Wars.Episode.1.The.Phantom.Menace.1999
如果你有C/C++编程背景,你可以意识到,这个格式与printf非常的类似。确实没错,每个待替换的字符串通过%开始,后面在字母表示待替换的字符串格式,例如:%d代表整数,%s代表字符串,%f代表浮点数。详细的格式请参见这里:String Formatting Operations。
除了上面这种指定类型的写法,还可以对占位符命名,然后通过一个字典类型来替换:
template2 = 'Star.Wars.Episode.%(number)d.%(title)s.%(year)d'
content = {'number': 2, 'title': 'Attack.of.the.Clones', 'year': 2002}
print(template2 % content)
它将输出:
Star.Wars.Episode.2.Attack.of.the.Clones.2002
第二种常用的格式化方法是字符串的format函数。例如:
template3 = 'Star.Wars.Episode.{}.{}.{}'
print(template3.format(3, 'Revenge.of.the.Sith', 2005))
它将输出:
Star.Wars.Episode.3.Revenge.of.the.Sith.2005
我们看到,格式化模板中的占位符是通过大括号的形式表达的。在format函数中,需要按顺序填入待替换的内容。
你也可以在大括号中指定待替换字符串的下标:
template4 = 'Star.Wars.Episode.{2}.{1}.{0}'
print(template4.format(1977, 'A.New.Hope', 4))
输出:
Star.Wars.Episode.4.A.New.Hope.1977
另外,你也可以通过命名的方式来指定
template5 = 'Star.Wars.Episode.{number}.{title}.{year}'
print(template5.format(number=5, title='The.Empire.Strikes.Back', year=1980))
它将输出:
Star.Wars.Episode.5.The.Empire.Strikes.Back.1980
集合
Python中的set类实现了数学中集合的概念。
集合中的一个元素只会出现一次,无论它被添加了多少次。集合中的元素是无序的。另外还有一个需要注意的是,集合中只能包含不可变对象(例如:数值和字符串),但是不能包含列表和字典,因为它们是可变的。
下面两种初始化方法效果是一样的:
set_a = set([1, 2, 3, 4, 5])
set_b = {3, 4, 5, 6, 7}
集合可以进行一系列的运算:求并集,求交集,求对称差集等。这些运算可以以方法形式调用,具体请查阅这里:Python Set Types。
除了方法调用,使用运算符的方式看起来会更简洁:
set_a = set([1, 2, 3, 4, 5])
set_b = {3, 4, 5, 6, 7}
print('set a:', set_a)
print('set b:', set_b)
print('----------------------')
print('a - b:', set_a - set_b)
print('a ^ b:', set_a ^ set_b)
print('a & b:', set_a & set_b)
print('a | b:', set_a | set_b)
这段代码输出如下:
set a: {1, 2, 3, 4, 5}
set b: {3, 4, 5, 6, 7}
----------------------
a - b: {1, 2}
a ^ b: {1, 2, 6, 7}
a & b: {3, 4, 5}
a | b: {1, 2, 3, 4, 5, 6, 7}
列表
列表是多个对象的集合。它可以包含不同类型的对象,并且可以嵌套。与字符串不同的是,列表是可变对象,你可以直接在原位置修改它。
列表通过[]或者list()初始化:
list_a = [1, 2, 3, 4, 5]
list_b = list('a', 'b', 'c', 'd', 'e')
| 操作 | 说明 |
|---|---|
| L1 + L2 | 拼接 |
| L * 3 | 重复 |
L.append(1) |
尾部添加 |
L.extend([2, 3, 4]) |
尾部扩展 |
L.insert(i, X) |
为位置i插入值X |
L.index(X) |
返回X的索引位置 |
L.count(X) |
统计X出现的次数 |
L.sort() |
排序 |
L.reverse() |
反转 |
L.copy() |
复制 |
L.clear() |
清除所有元素 |
L.pop(i) |
删除i处元素,并返回 |
L.remove(X) |
删除元素X |
del L[i] |
删除i处元素 |
del L[i:j] |
删除i到j处元素 |
L[i:j] = [] |
删除i到j处元素 |
L[i] = 3 |
索引赋值 |
下面是一段代码示例:
list_a = [1, 2, 3, 4, 5]
print('a:', list_a)
list_a.append(1);
print('after append 1, a:', list_a)
list_a.extend([1,2,3])
print('after extend [1, 2, 3], a:', list_a)
print("index of '1' in a:", list_a.index(1))
list_a.sort()
print('after sort, a: ', list_a)
list_a.reverse()
print('after reverse, a:', list_a)
list_a.remove(1)
print('after remove(1), a:', list_a)
del list_a[1:3]
print('after del a[1:3], a:', list_a)
list_b = list('abcde')
print('b:', list_b)
list_c = list_a + list_b
print('a + b:', list_c)
它的输出如下:
a: [1, 2, 3, 4, 5]
after append 1, a: [1, 2, 3, 4, 5, 1]
after extend [1, 2, 3], a: [1, 2, 3, 4, 5, 1, 1, 2, 3]
index of '1' in a: 0
after sort, a: [1, 1, 1, 2, 2, 3, 3, 4, 5]
after reverse, a: [5, 4, 3, 3, 2, 2, 1, 1, 1]
after remove(1), a: [5, 4, 3, 3, 2, 2, 1, 1]
after del a[1:3], a: [5, 3, 2, 2, 1, 1]
b: ['a', 'b', 'c', 'd', 'e']
a + b: [5, 3, 2, 2, 1, 1, 'a', 'b', 'c', 'd', 'e']
字典
字典(Dictionary)也是软件开发中非常常用的类型。这种类型在其他编程语言中通常叫做Map。
无论是Dictionary还是Map,它们都是“键:值”对的方式存储数据。
与集合还有列表类似,字典也有两种初始化方式:{}或者dict()。如果你有两个一一对应的数组,你可以使用zip函数将它们映射成字典。
字典中的键和值可以任意添加,对同样的键赋值将覆盖原先的值。但需要注意的是,字典中的键并不存在什么特定的顺序,如果有需要,你要另外对键进行排序。字典的值可以是其他任何数据类型,甚至是另一个字典或者列表,这意味着字典类型支持嵌套。
字典的常见操作如下:
| 操作 | 说明 |
|---|---|
dic.keys() |
返回所有键 |
dic.values() |
返回所有值 |
dic.items() |
所有“键 + 值”元组 |
dic.copy() |
复制 |
dic.clear() |
清除所有条目 |
dic.get(key, default?) |
通过键获取,如果不存在返回default值 |
dic.pop(key, default?) |
通过键删除,如果不存在返回default值 |
dic.popitem() |
删除并返回所有键值对 |
dic[key] = 42 |
通过键赋值 |
del D[key] |
根据键删除条目 |
下面是一段代码示例:
paul = dict(Name='Paul', Hobby=['Music', 'Photograph'], Job='Developer')
moira = dict(zip(['Name', 'Hobby', 'Job'], ['Moira', 'Movie', 'Student']))
family = {'People': [paul, moira], 'City': 'Nanjing'}
print('paul.keys:', paul.keys())
print('paul.values:', paul.values())
print('paul.City:', paul.get('City', 'Nanjing'))
print('Family, city:', family['City'])
for p in family['People']:
print('\t', p)
print("Moira's hobby is:", moira['Hobby'])
paul['Hobby'] = ['Rock', 'Computer']
print('paul:', paul)
del paul['Hobby']
print('paul:', paul)
这段代码输出如下:
paul.keys: dict_keys(['Name', 'Hobby', 'Job'])
paul.values: dict_values(['Paul', ['Music', 'Photograph'], 'Developer'])
paul.City: Nanjing
Family, city: Nanjing
{'Name': 'Paul', 'Hobby': ['Music', 'Photograph'], 'Job': 'Developer'}
{'Name': 'Moira', 'Hobby': 'Movie', 'Job': 'Student'}
Moira's hobby is: Movie
paul: {'Name': 'Paul', 'Hobby': ['Rock', 'Computer'], 'Job': 'Developer'}
paul: {'Name': 'Paul', 'Job': 'Developer'}
元组
最后,我们还要学习的一种类型叫做元组(Tuple)。
元组也是对象的组合。它其中包含的元素是有序的,通过下标访问其中的元素。它可以包含不同类型的元素。
元组与列表有些相似,但最大的不同在于元组是不可变对象,这意味着你不能原地修改它。
元组可以通过()或者tuple初始化。
元组常见的操作如下:
| 操作 | 说明 |
|---|---|
| t1 + t2 | 拼接 |
| t * 3 | 重复 |
| t.count(‘a’) | 返回元素出现次数 |
| t.index(‘a’) | 返回第一次找到的元素下标 |
下面是一个代码示例:
t1 = (1, '2', (3, 4))
t2 = tuple([1, '2', [3,4]])
t3 = t1 + t2
print('len(t3): ', len(t3))
print('t3.count(1): ', t3.count(1))
print("t3.index('2'): ", t3.index('2'))
结果如下:
len(t3): 6
t3.count(1): 2
t3.index('2'): 1
成员关系与迭代
对于字符串,集合,列表,字典和元组几种包含了多个元素的数据类型来说,它们有一些共同的操作:
- 通过
in确认成员关系。注意:对于字典来说,in是指键所组成的集合。 - 通过
for x in y来遍历其中的元素。 - 来遍历的时候,你可以使用表达式创建新的数据。
t = (1, '2', 3.0)
l = [1, 2, 3.0]
s = {1, '2', 3.0}
d = {'Name': 'Paul', 'Hobby': ['Music', 'Photograph']}
str = 'Attack.of.the.Clones'
print('1 in', t, ':', 1 in t)
print('1 in', l, ':', 1 in l)
print('1 in', s, ':', 1 in s)
print('"Name" in', d, ':', 'Name' in d)
print('"Attack" in', str, ':', "Attack" in str)
print('\nelements in list:')
for x in l:
print('\t', x)
print('\n')
new_l = [x ** 2 for x in l]
print('new_l:', new_l)
这段代码输出如下:
1 in (1, '2', 3.0) : True
1 in [1, 2, 3.0] : True
1 in {1, 3.0, '2'} : True
"Name" in {'Name': 'Paul', 'Hobby': ['Music', 'Photograph']} : True
"Attack" in Attack.of.the.Clones : True
elements in list:
1
2
3.0
new_l: [1, 4, 9.0]
索引和分片
对于有序集合(字符串,列表,元组)来说,它们都支持被称之为索引和分片的操作方式。
对于字典来说,它仅支持通过键值索引操作,但不支持分片。
索引是通过下标来访问指定位置的元素。这种操作在其他语言中也很常见,例如Java和C++。但Python的索引不仅支持0和正整数,它还支持负整数,例如:str[-2],这意味着访问倒数第二个元素。一般的,对于一个有序集合l来说,l[-n]意味着倒数第n个元素,即:l[len(l)-n]。
另外,分片(slice)就是Python所特有的操作了。分片支持下面这样的语法:
l[:]是指获取集合l中的所有元素l[n:m]是指获取[n, m)范围内的元素l[:9]是指获取[0,9)范围内的元素l[n:]是指获取第n个开始到末尾的元素l[:-n]是指获取[0, len(l)-n)范围内的元素l[n:m:d]是指获取[n, m)范围内的元素,但是每隔d次取一个元素
这样说起来很费劲,但是如果直接看代码可能就很好理解了:
str = "Star.Wars.Episode.4.A.New.Hope.1977"
print('str[:]:', str[:])
print('str[5:9]:', str[5:9])
print('str[:9]:', str[:9])
print('str[5:]:', str[5:])
print('str[:-8]:', str[:-16])
print('str[::2]', str[::2])
这段代码输出如下:
str[:]: Star.Wars.Episode.4.A.New.Hope.1977
str[5:9]: Wars
str[:9]: Star.Wars
str[5:]: Wars.Episode.4.A.New.Hope.1977
str[:-8]: Star.Wars.Episode.4
str[::2] Sa.asEioe4ANwHp.97
变量与对象
尽管在很多时候我们不用区分变量(variable)与对象(object)的区别,但如果搞懂它们将对你分析一些微妙问题有很大的帮助。
Python与其他语言有一个很大的区别是:Python中的变量不需要声明类型。实际上,变量本身并不存在类型,类型是对象才有的属性。
简单来说,变量就像是一个手柄,它是一个有实际名称的实体,但是它并不存储值。对象才是实际存储值的实体,你需要通过变量来使用对象。
当你定义一个变量并指定值时,Python实际上是创建了一个对象来存储值,然后将变量指向它。如下图所示:
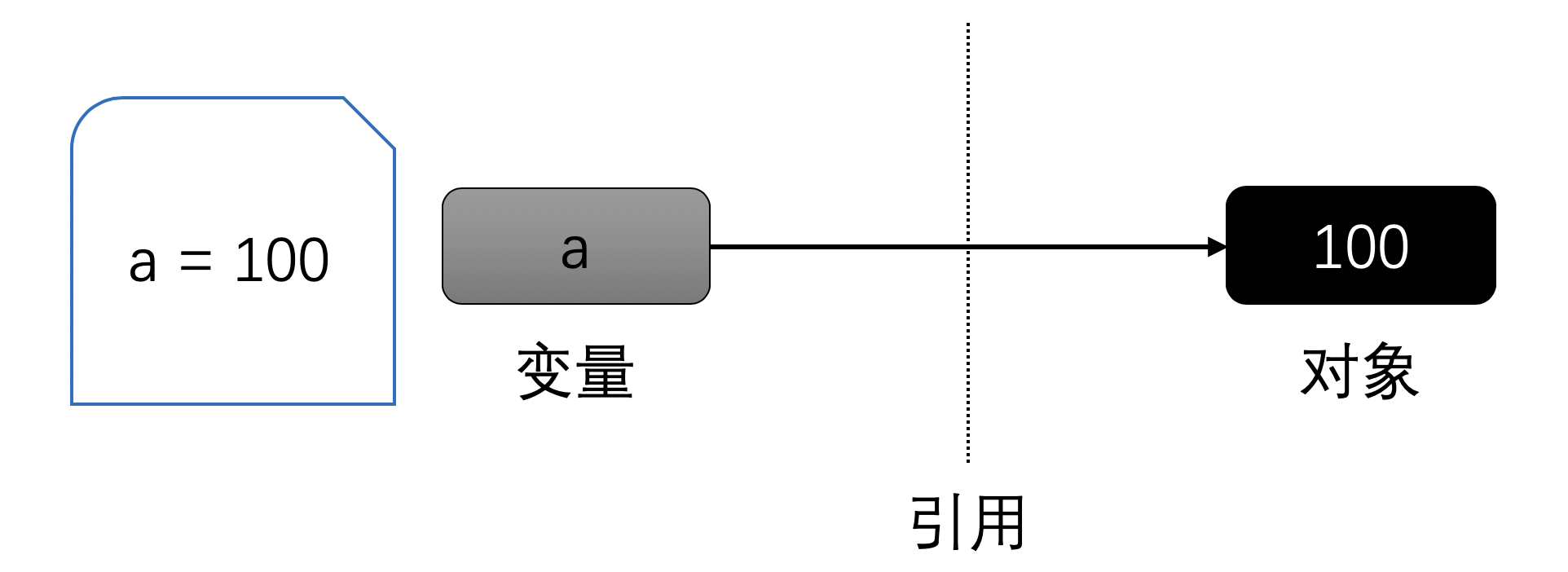
如果接下来你又创建了另外一个变量并通过原先的变量赋值,那么此时两个变量将指向同一个对象:
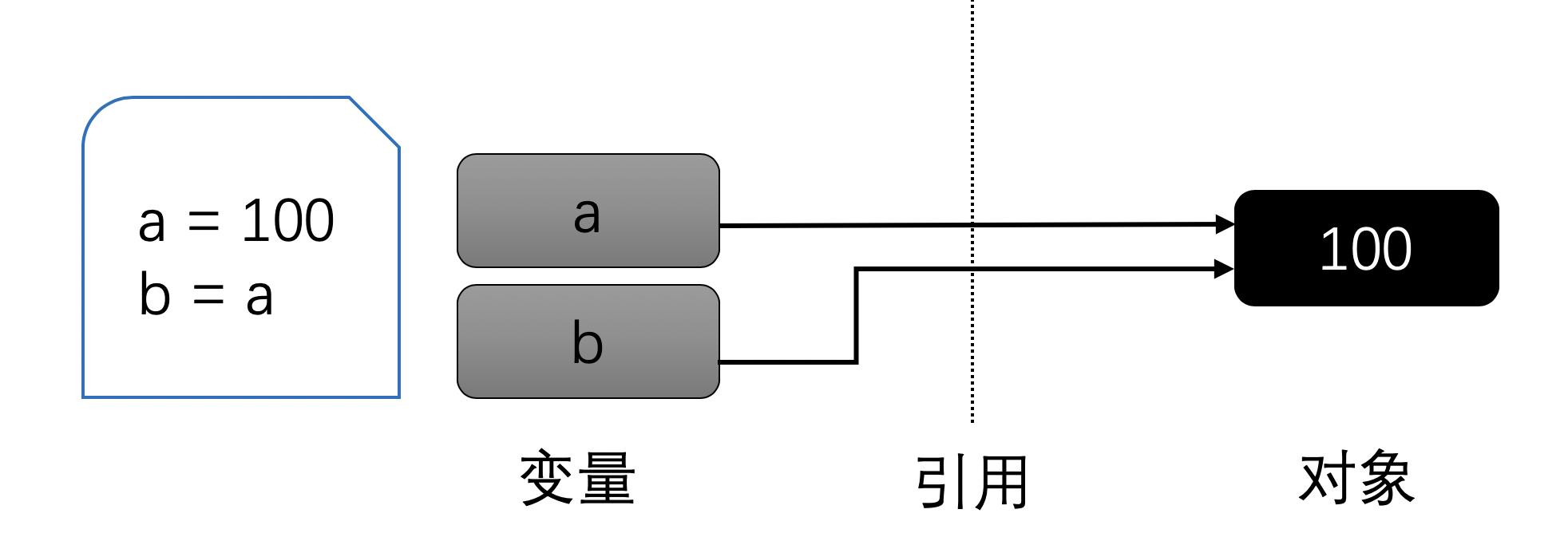
接下来,如果你又对b进行了一次新的赋值,那么它们将指向不同的对象:
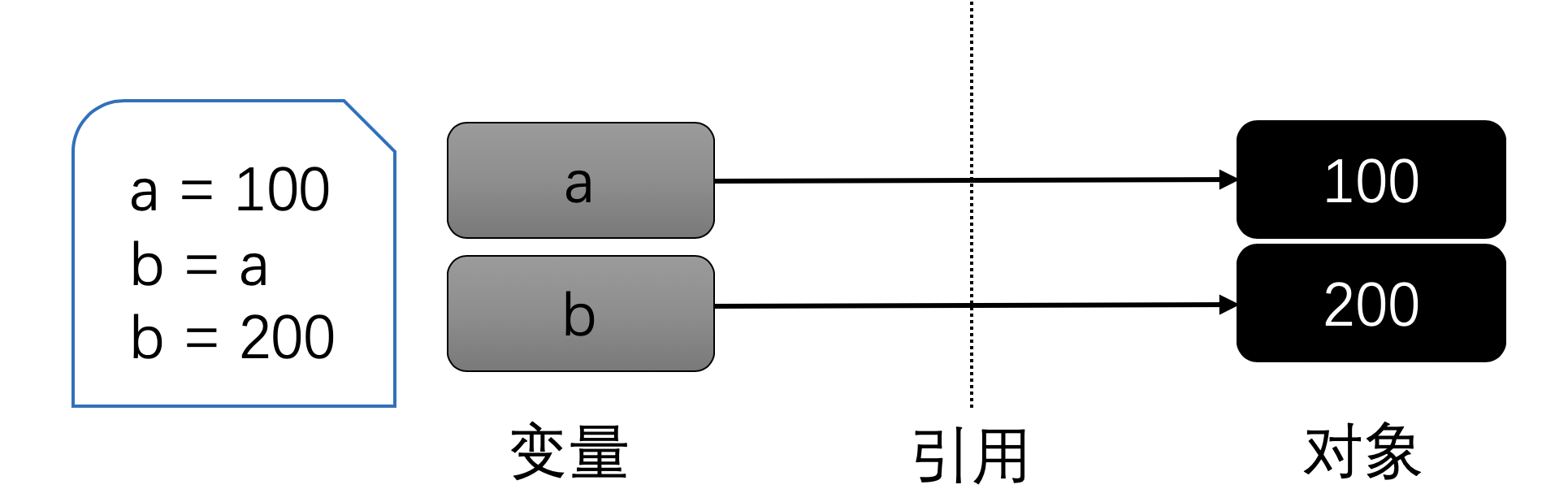
上面我们看到的是不可变的数字对象。因此我们只能对变量重新赋值,而不能修改它。
当如果两个变量指向同一个可变对象,情况就会不一样:
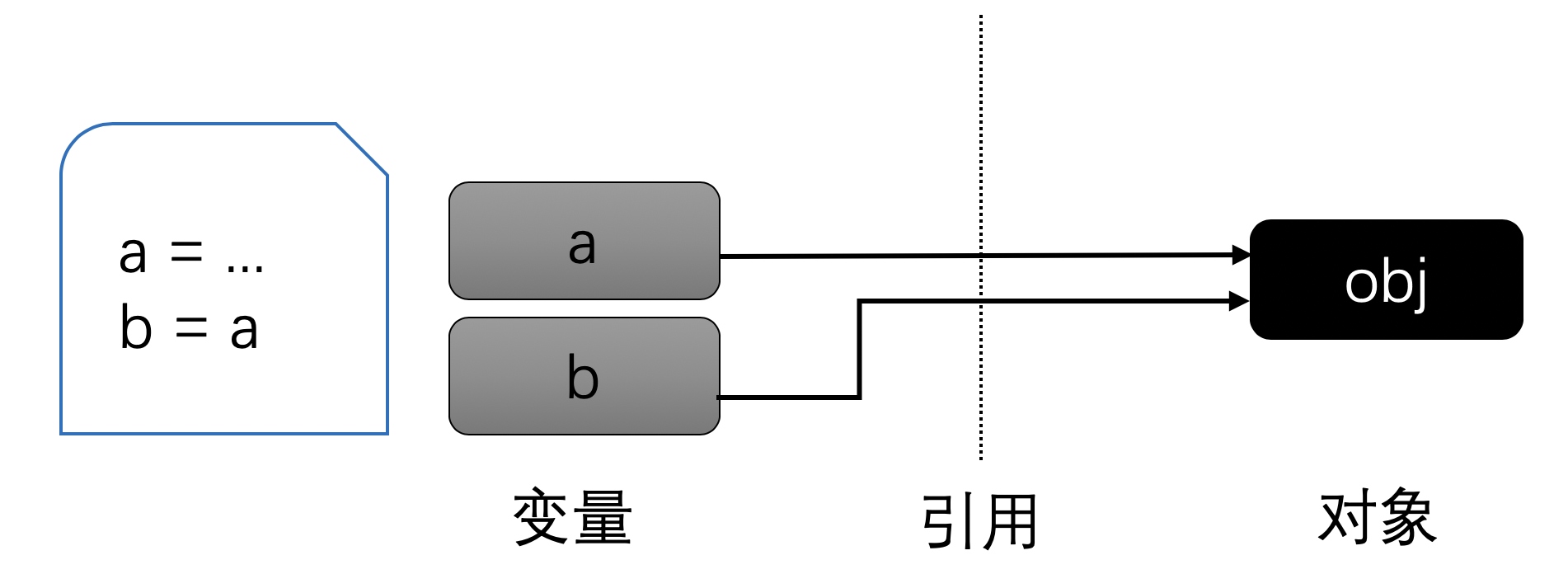
此时,如果通过任何一个变量修改对象的值,因为这个对象在两个变量之间共享,因此通过另外一个变量读取值时也会反映出来。
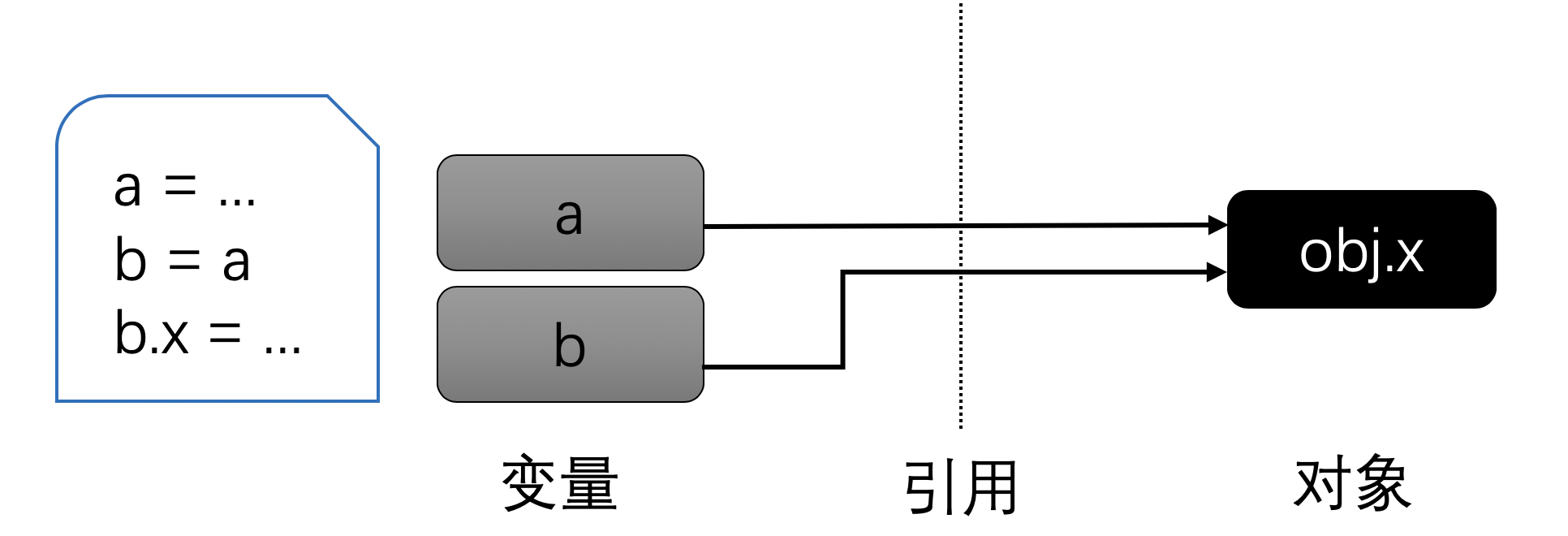
如果你熟悉C/C++中的指针,你会发现这和指针非常的相似,只不过我们没有使用
*符号。
==和is
有了上面的铺垫,理解==和is就很容易了:
==是判断两个对象的值是否相等is是判断两个变量是否指向同一个对象
因此,下面这段代码,两个判断结果都是True。
a = 100
b = a;
print('a==b:', a==b)
print('a is b:', a is b)
如果接着将b赋值100会怎么样?它会指向一个新的对象吗?
b = 100
print('a==b:', a==b)
print('a is b:', a is b)
答案是否定的,这里两个判断仍然都将是True。因为同一个数字对象在运行时会被共享。
如果是可变对象呢:
a = [1, 2, 3]
b = a
print('a==b:', a==b)
print('a is b:', a is b)
a[2] = 100
print('a:', a)
print('b:', b)
b = [1, 2, 100]
print('a==b:', a==b)
print('a is b:', a is b)
毫无疑问,这里的第一处两个判断都将是True。因此当进行a[2] = 100操作时,对b也会有影响。
不过,如果重新对b进行赋值:b = [1, 2, 3],它将指向一个新的对象,因此最后的判断a==b将一次返回True,a is b将返回False。
上面这段代码将输出如下:
a==b: True
a is b: True
a: [1, 2, 100]
b: [1, 2, 100]
a==b: True
a is b: False